Hablando de SEO, todo el mundo está dedicado a adelantarse a sus competidores, con sus conocimientos o contando con los servicios de una agencia de posicionamiento web, pero la realidad es que siempre hay precursores que se clasifican mejor en una lista de palabras clave.
¿Cómo hacer que tu SEO funcione mejor? Aquí hay 3 trucos de web scraping que pueden ayudarte a optimizar tu SEO.
Truco 1: Optimización del Sitemap (Mapa de Sitio)
¿Por Qué el Mapa de Sitio XML es Importante?
Los mapas de sitio XML son un archivo que ayuda a Google Spider a rastrear e indexar las URLs importantes de un sitio web. Por lo tanto, un excelente mapa de sitio XML debe estar “actualizado, libre de errores e indexable”.
Optimizarlo es ayudar a Google Spider a conocer mejor el sitio web, lo que conduciría a una mejor clasificación. Funciona significativamente cuando estás trabajando un sitio web de tamaño medio. Por ejemplo, si está trabajando un sitio web de comercio electrónico en shopify.com o trabajando para tu propio blog en worldpress.com, esto te ayudaría a obtener una mejor clasificación.
¿Cómo optimizar tus mapas de sitio XML?
Si has usado/escuchado un programa como Screaming Frog, entonces ya conoces el web scraping en cierto punto. El mecanismo de trabajo de los programas es scrapear metadatos, como el título, la meta descripción, palabras clave, etc. de todas las páginas web que están bajo un dominio.
Para optimizar tus mapas de sitio XML, se recomienda utilizar el Generador de mapas de sitio XML de Screaming Froge. Es un rastreador prediseñado que funciona para extraer todo el HTML del sitio web y generar un archivo de Excel perfecto para que la gente lo optimice.
Además, puedes intentar usar una herramienta GRATUITA de web scraping para crear un mapa de sitio XML tu mismo.
Truco 2: Optimización de Página Web
La optimización de la página web tiene como objetivo ayudar a Google a leer e indexar el contenido de un sitio web de una manera más fácil y rápida, o para satisfacer las preferencias de los visitantes. Por lo tanto, es mejor si el HTML de un sitio web se ajusta a los algoritmos de clasificación de Google.
Aparte del contenido, el factor más importante en el HTML podría ser la etiqueta H1. Google spider lo toma como el núcleo de la página.
Destacar con H1 Etiqueta
Según Neilpatel, “el 80% de los resultados de búsqueda de la primera página en Google utilizan un h1”.
Aunque las etiquetas principales son importantes para la clasificación, debemos prestar mucha atención a las metaetiquetas, que son los factores de conversión más sencillos.
Por lo tanto, la forma más práctica de mejorar la clasificación de un sitio web es optimizar las etiquetas de forma regular. Una acción pequeña pero poderosa que todos deberían tomar.
En septiembre de 2009, Google anunció que los algoritmos de clasificación de Google no incluían ni la meta descripción ni las palabras clave para la búsqueda web. Sin embargo, no podemos negar que tiene un gran impacto en la tasa de clics. Por lo tanto, será mejor que hagamos un trabajo de optimización tanto en la meta descripción como en las etiquetas de título.
Sugerencias: para obtener más información sobre por qué la meta descripción y la etiqueta de título son importantes, consulta la Meta descripción y la etiqueta de título de Moz.
¿Cómo usar web scraping para optimizar tu página web?
Para hacerlo práctico, simplemente sigue los pasos a continuación y obtendrás información sobre etiquetas y metadescripciones perfectamente organizada para tu examinación posterior.
Antes de comenzar, descarga Octoparse e instálalo en tu computadora. Como estás equipado con esta herramienta de web scraping, te mostraré cómo obtener las etiquetas necesarias en todos los blogs de Octoparse como ejemplo. Puedes hacerlo para cualquier otro dominio.
Paso 1: Inicia Octoparse e ingresa la URL de destino en el cuadro. Haga clic en el botón “Inicio“.

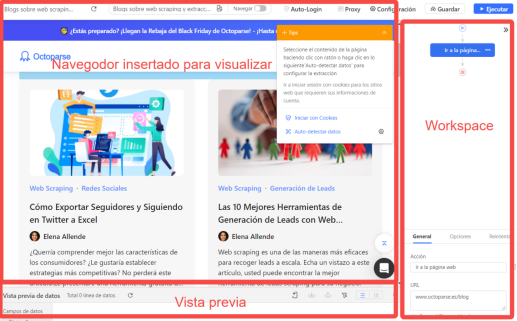
Paso 2: Como podemos ver 3 zonas:
- El navegador integrado de Octoparse,donde puedes interactuar
- En el lado derecho, hay un área de flujo de trabajo donde podemos personalizar la acción según nuestras necesidades.
- En abajo hay una zona para ver la vista previa de los datos
Ahora, creamos una paginación para recorrer todas las páginas del blog y un elemento de bucle para visitar cada blog. Simplemente haz algunos clics como muestra la siguiente imagen.
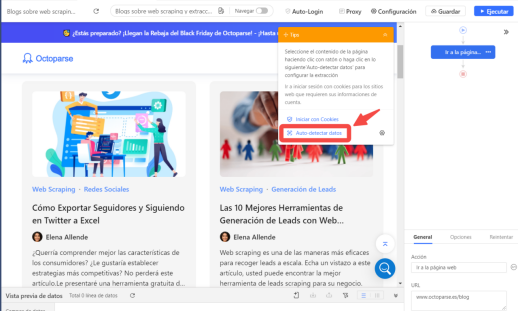
Paso 3: Extrae la información necesaria (títulos, meta descripciones, etiquetas de título)
- Usa la función Auto-Detectar
- Crea un flujo de trabajo
Paso 4: Ejecutar el flujo. Hay dos opciones:
- Ejecutar en local significa que el flujo se va a ejecutar en local sin usar recursos Cloud y necesitas permanecer encendido tu dispositivo.
- Ejecutar en la nube puedes quitar el limite del dispositivo, el flujo se va a ejecutar en la nube.


Básicamente, podemos pasar por todos los factores importantes de Excel.
- Verifica por lotes si la longitud de las meta etiquetas funciona mejor en el resultado de búsqueda de Google.
- Inspecciona por lotes la etiqueta H1, asegurándote de que solo haya una etiqueta H1 para una sola página y que la longitud del carácter esté dentro de un rango adecuado.
Este es el estándar que podríamos tomar como referencia en School4Seo.
Además de la información de arriba, podemos recopilar más información sobre tus blogs, como la categoría, el número de compartir, el número de comentarios, etc., para explorar los problemas de tu sitio web.
¿Cómo encontrar elementos de páginas web con XPath?
Si fracasas en conseguir los datos que necesitas, es posible que debas modificar el Xpath para ubicar con precisión el elemento que deseas. Esto se debe a que las páginas web tienen una estructura diferente y un robot puede no ser aplicable a todas.
“XPath juega un papel importante cuando usas Octoparse para extraer datos. Reescribirlo puede ayudarte a tratar con páginas faltantes, datos faltantes o duplicados, etc. Puede que el XPath parezca intimidante al principio, pero en realidad, no es así. En este artículo, presentaré brevemente XPath y, lo más importante es que, te mostraré cómo se puede usar para obtener los datos que necesitas mediante la creación de tareas precisas”.
Truco 3: Curación del Contenido de Blog
La curación de contenido es una forma en que las personas seleccionan las piezas más valiosas de las páginas web y agregan valores a la información recopilada. SEO es una aplicación popular de curación de contenido. El contenido curado se pone de moda en Google, lo que ayuda a clasificar los sitios web en un lugar mejor para el resultado de búsqueda.
¿Cómo puede ayudarte Web Scraping a curar el contenido?
Un caso de uso típico es el marketing de fuentes RSS. La ventaja de RSS es enviar el contenido a tus usuarios automáticamente, en lugar de obligarlos a visitar tu sitio web todos los días. Ahora, la pregunta es, ¿cómo obtener suficiente contenido para el feed RSS?
Imagina que si eres un bloguero que se enfoca en asuntos legales. Entonces tus audiencias son aquellas que tienen gran interés en la próxima información sobre la ley o algunos materiales de estudios de casos. En este caso, el web scraping puede ayudarte a recopilar la información con una frecuencia determinada para fines de RSS.
Por ejemplo, con nueva funciones de Octoparse, podemos recopilar la información del caso y obtener la información para tu fuente RSS.
Para Terminar
Después de recopilar y analizar todos los datos necesarios, probablemente tendrás que actualizar tu estrategia de marketing y SEO, cambiar algunas palabras clave y contenidos, y prestar atención constantemente a los cambios diarios.
Ten en cuenta que el ranking del algoritmo del motor de búsqueda de Google es un ecosistema vivo, que cambia todo el tiempo. así que debes permanecer atento a los datos actualizados del web scraping para optimizar la creación de contenidos, llegar a la primera página de resultados de búsqueda, y atraer más clientes e ingresos.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



