Extraer datos de un archivo HTML es literalmente lo mismo que copiar y pegar la información de una página web pero con alguna herramienta que te puede ayudar a realizarlo en un abrir y cerrar de ojos. Puede parecer sencilla la extracción manual, pero imagina que tuvieras que extraer miles de textos, imágenes, títulos o URLs, entonces sería un trabajo agotador. De hecho, la extracción de datos desde las páginas web tiene varios usos prácticos. Por ejemplo:
- Descargar blogs desde páginas web o todos los artículos desde una página web específica.
- Scrapear informaciones de producto como SKU, modelo, imagen, descripción desde sitios web de Comercio Electrónico (Amazon, eBay, Mercado Libre, el Corté Inglés, etc.)
- Extraer datos desde las tablas o imágenes o limpiar los HTML desordenados de un archivo incluyendo solo la parte de contenido leíble.
¿Cómo se ingresa el texto en un archivo HTML?
Sin importar la razón por la que necesites extraer texto de un archivo HTML, este artículo te ayudará a aprender un poco sobre cómo se ingresan los textos o los diferentes tipos de datos en un archivo HTML antes de ponerse a trabajar.
El componente principal de un archivo HTML es un conjunto de elementos en los que se incrusta todo tipo de datos, incluido el texto. Estos elementos se disponen de una manera determinada para formar una página web.
Este es un ejemplo tomado de uno de los ejercicios de HTML de W3School:
Podrías considerar lo de arriba como un element. <p> y </p> como los tags(el primero marca un comienzo y el segundo un final)
Entender la estructura de un archivo HTML sería útil si solo se desea extraer un dato concreto del archivo HTML (o de la página web). Y así es exactamente como entraría en juego Xpath: un lenguaje de consulta para seleccionar elementos de un documento XML/HTML.
Extraer texto de HTML utilizando un lenguaje de programación
Hay dos formas que puedes probar para capturar texto de archivos HTML.
Lenguaje de programación
Para aquellos documentos HTML sencillos, las personas que tienen conocimientos básicos de codificación optarían por escribir un programa para eliminar todas las etiquetas HTML y conservar solo el texto dentro de los archivos HTML, utilizando Expresiones Regulares o XPath. Hay varios lenguajes de programación ampliamente utilizados como C#, Java, Python, JS, PHP, Go y NodeJs que están disponibles para los programadores informáticos.
Algunos de estos lenguajes tienen su propio parser (analizador sintáctico) para HTML y lo proporcionan de forma gratuita y podrías saber más sobre estos parsers de HTML haciendo clic aquí.
Probar y depurar tus códigos puede costar algo de tiempo, lo cual debería ser bien previsto si has tenido alguna experiencia con la codificación.
Herramienta de Extracción de Datos de Página Web
Existen muchas y potentes herramientas de extracción, como Octoparse, que te permiten recoger casi todo lo que hay en la página web, incluyendo el texto, los enlaces, las imágenes, etc. Puedes convertir todo lo que obtengas en un formato de datos estructurados.
No es necesario realizar ninguna codificación, por lo que es bueno para aquellos que no tienen experiencia en codificación. En la mayoría de los casos, no se obliga a escribir Expresiones Regulares o XPath, lo que siempre será una ventaja si tienes requisitos de datos complicados. Octoparse, al estar diseñado para personas que no son programadores, viene con una interfaz fácil de usar que les permite interactuar fácilmente con las páginas web. Es fácil gestionar y exportar los datos sin necesidad de un IDE.
Consejos: Si no eres un programador, el modo de detección automática de Octoparse te resultará muy útil para empezar. El software detectará la página web automáticamente y tendrás los valiosos datos organizados en una hoja de cálculo.
Aquí hay algunas guías prácticas que pueden interesarte:
Extraer datos de eBay con el algoritmo de auto detección
Guía complete de la detección automática
Ejemplo de extracción de HTML
Si todavía eres un novato en cualquier lenguaje de programación pero quieres descargar información de páginas web, una herramienta de raspado web puede ser extremadamente útil. El algoritmo de auto-detección de Octoparse(imágenes, URLs, títulos, precios, descripciones, etc.) hace que el raspado de datos sea fácil para los no-codificadores. Para conseguir la mayoría de las páginas web solo hay tres simples pasos:
- Introducir la URL de destino
- Iniciar la autodetección
- Ejecutar la tarea para el raspado de datos
Estoy tomando esta página como ejemplo: https://www.jornada.unam.mx
Si quieres raspar las noticias de un periódico (o cualquier otro sitio web similar), simplemente introduce la URL en Octoparse y activa la autodetección, obtendrás un raspador que te ayudará a obtener los datos estructurados como se indica a continuación:
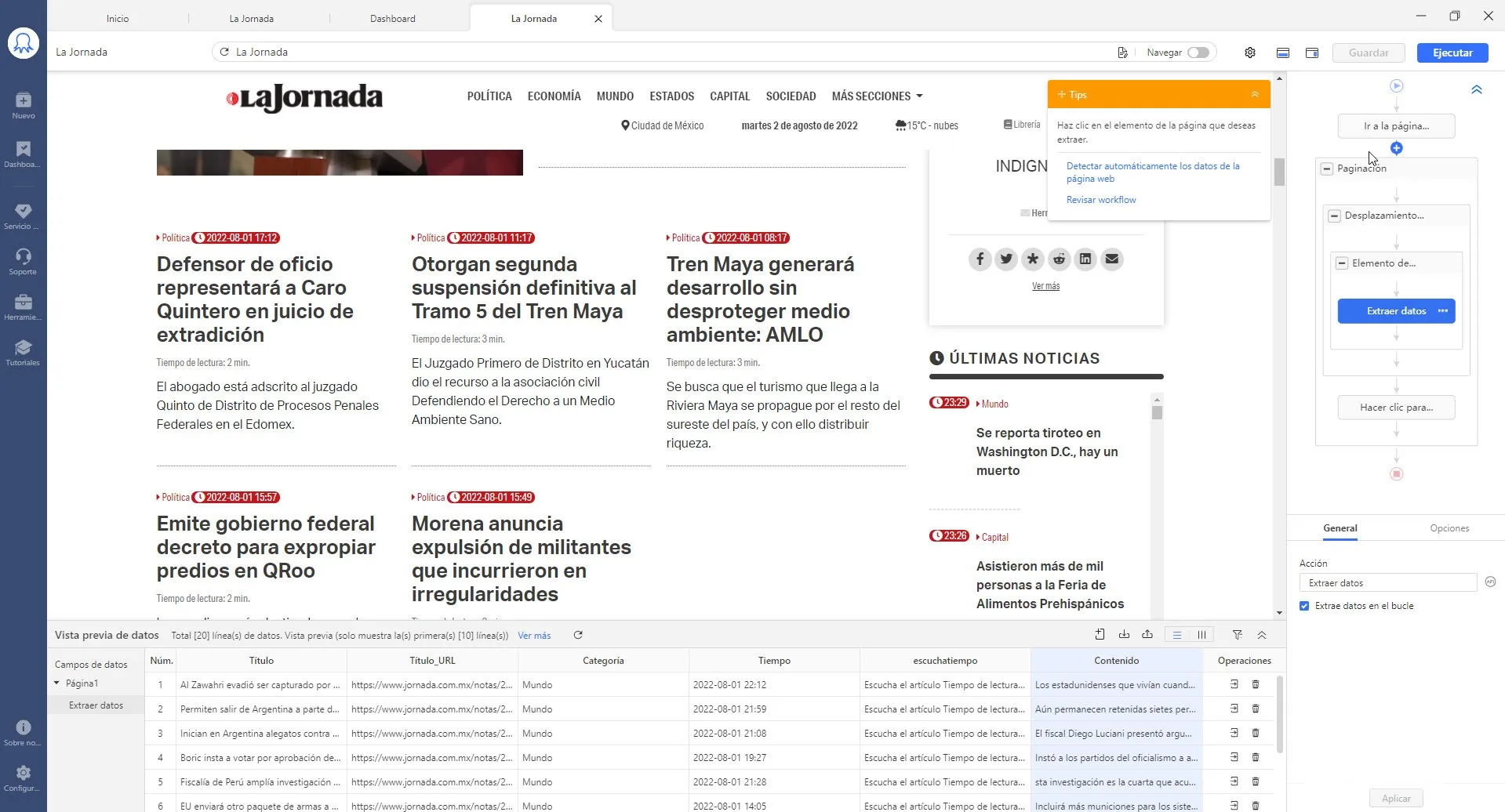
Al hacer clic en el botón Guardar, tendrás un raspador a tu disposición. Puedes ejecutar el scraper en cualquier momento que necesites los datos o programarlo para extraerlos regularmente.
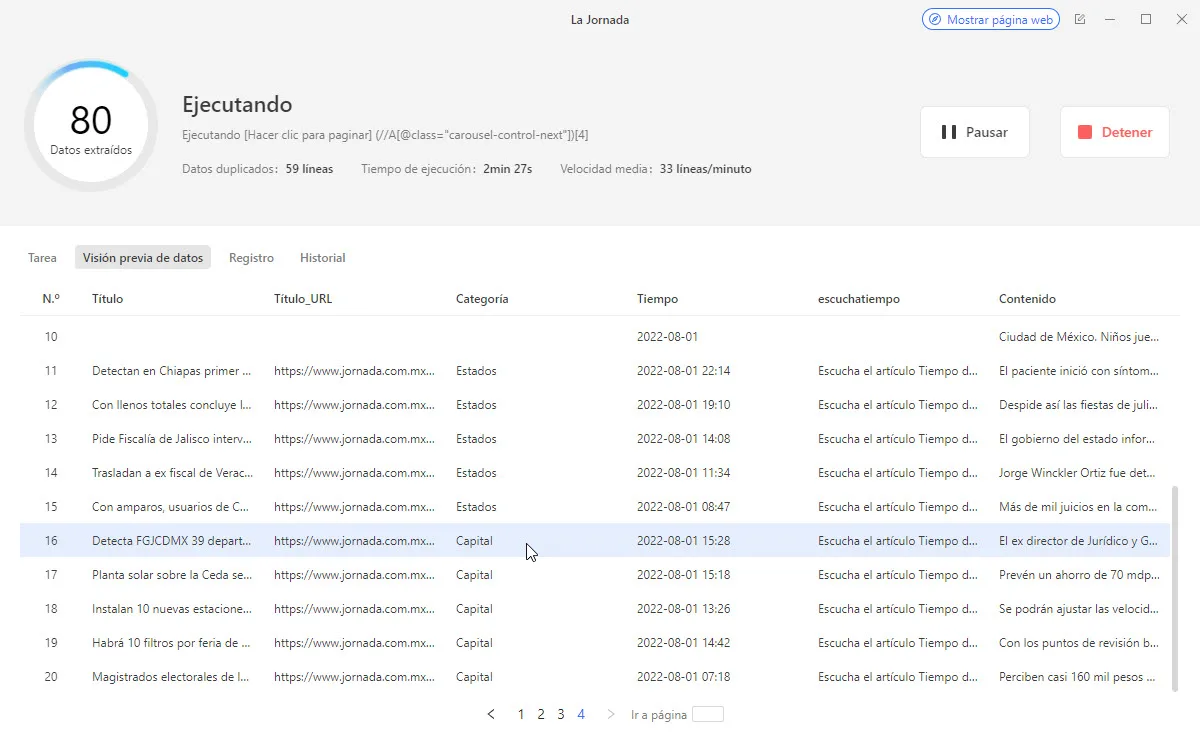
Si optas por las ejecuciones locales, podrás ver el proceso funcionando en tiempo real. Cuando la tarea esté terminada, podrías descargar los datos en Excel, CSV o JSON. Con la ayuda de Octoparse, la extracción de datos de un archivo HTML puede ser así de fácil.
¡Descarga Octoparse ahora y empieza la exploración ahora!

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



