Como puedes notar, en muchos casos necesitamos guardar una lista de imágenes de un sitio web y esto puede ser un trabajo agotador y tedioso con solo hacer clic y guardar las imágenes una por una.
De hecho, una herramienta de web scraping es una opción perfecta para automatizar este trabajo. En lugar de hacer clics interminables en las páginas web, solo necesitas configurar una tarea en 5 minutos y el robot obtendrá todas las URL de las imágenes. Cópialos en un descargador de imágenes masivo, hará las cosas en solo 10 minutos.
Cómo obtener imágenes de un sitio web
El primer paso es descargar la herramienta de web scraping en tu computadora. Octoparse es la herramienta que usaremos en esta tarea. No te preocupes. Esta es una guía infalible y no necesitas ninguna experiencia en programación para comenzar.
Nota: Octoparse ofrece un plan gratuito para todos nuestros usuarios. No es necesario que pagues por ninguna de las funciones mencionadas en esta guía.
Obtener todas las URLs de imágenes en 3 pasos
#Paso 1: Crear una tarea
1)Inicia Octoparse. Ingresa la URL de la página web de la que queremos extraer datos. Luego haz clic en el botón “Iniciar” para continuar.

Sample URL:
(Si este enlace no es válido, usa otro enlace de listado de productos en Aliexpress)
A medida que la página se carga en el Octoparse, verás el Panel de sugerencias en la esquina superior derecha y haz clic en “Detectar automáticamente los datos de la página web” para continuar con la detección automática. La detección automática es una función que puede ayudarte a detectar y seleccionar datos valiosos en la página. Ni siquiera necesitas apuntar y hacer clic, Octoparse ofrece opciones para ti.
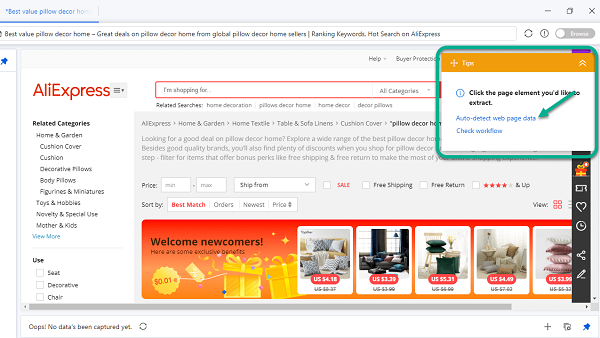
3)A medida que se complete la detección, aparecerá un cuadro de vista previa de datos donde puedes verificar qué datos estás obteniendo del conjunto actual. Haz clic en “Cambiar resultados de detección automática” para elegir entre diferentes opciones. Haz clic en “Crear flujo de trabajo” para confirmar y crear una tarea.
¡Listo! ¡Ahora has construido tu raspador de Aliexpress!
#Paso 2: Editar la tarea
En este paso, chequeamos la paginación y modificaremos el XPath si es necesario. ¿Qué es la paginación? Bueno, es una configuración que permite que el raspador haga clic en las páginas, de modo que cuando termine de scrapear la página actual, hará clic en la página siguiente y continuará el scraping.
1)Verifica el flujo de trabajo creado por Octoparse a la izquierda y haga clic en el ciclo “Paginación”. Desplázate hacia abajo en la página en el navegador integrado hasta donde se encuentra el botón “Siguiente” para que podamos ver si el crawler ha seleccionado el botón correcto para pasar las páginas.
2)La imagen muestra que el scraper ha seleccionado el botón “Anterior” (en el rectángulo rojo) en lugar de “Siguiente”. Hacer clic en Anterior no es una forma de pasar páginas, robot. Vamos a corregirlo.
3)Haz doble clic en el bucle de Paginación, llegará a la interfaz de configuración. En la barra hay una línea de código, que es Xpath creado automáticamente para ubicar el botón “Siguiente”. ¿Cómo modificarlo? Haz clic en la pequeña flecha a la derecha y haZ clic en el botón “Siguiente” en el navegador. Sí, le estás diciendo al robot, oye, este es el botón en el que quiero hacer clic. Bastante simple, ¿verdad?
4)El último movimiento del paso es configurar los desplazamientos automáticos. Esto puede garantizar que la página se cargue por completo antes de que se realice el raspado real. ¡Basta con unos pocos clics!
5)Regresa al flujo de trabajo y haz doble clic en “Ir a la página web”, ve a “después de cargar la página” y marca “desplázate hacia abajo en la página después de que se haya cargado”, establece un desplazamiento hacia abajo 50 veces con medio segundo entre 2 desplazamientos .
Felicidades. ¡Ahora has configurado correctamente un scraper!
#Paso 3: Ejecutar la tarea
Simplemente haga clic en el botón “Ejecutar” de arriba y ejecuta la tarea en tu dispositivo. Obtendrás miles de líneas de datos en unos minutos. ¡Esa es la velocidad de Octoparse! Una vez que aprendas esto, te arrepentirás de perder el tiempo en trabajos manuales que obtienen datos web en los primeros días.
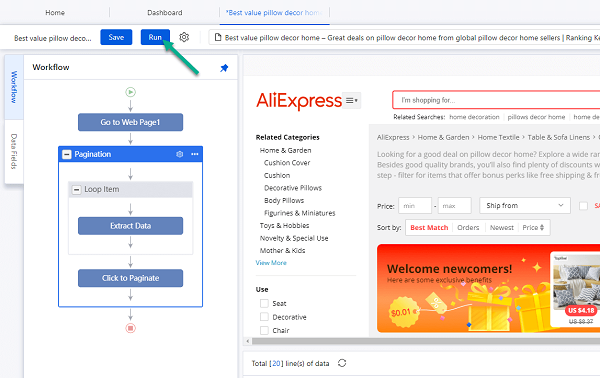
Estos son los datos que me obtuvo Octoparse en 5 minutos. De hecho, no solo scrapea todas las URLs de las imágenes, sino también los detalles correspondientes del producto. Esto podría ser extremadamente útil para las personas que realizan investigaciones de productos y análisis de comercio electrónico.
Descargar imágenes de forma masiva en unos segundos
Con todas las URL de imágenes en un archivo de Excel, lo que necesitas ahora es una herramienta de descarga masiva. Recomendaría la extensión de Chrome: Tab Save.
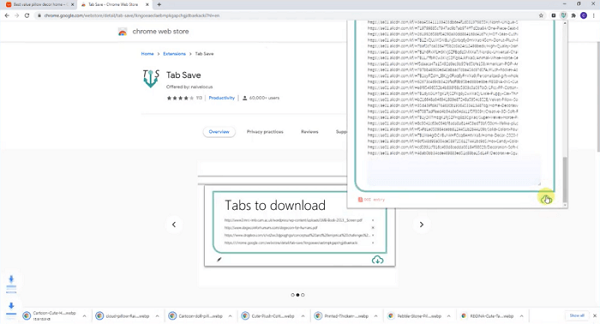
Copia y pega las URLs de la imagen en Tab Save y haz clic para descargar, todas las imágenes se guardarán en tu computadora en segundos.
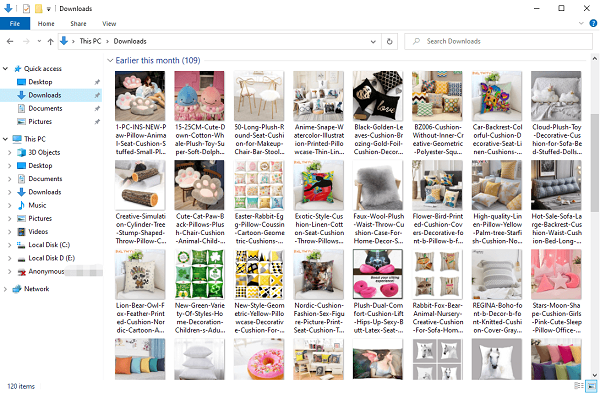
Todo el proceso puede tardar solo 10 minutos y obtendrás miles de imágenes (incluso los detalles del producto en consecuencia) de Aliexpress. ¡Vamos, definitivamente vale la pena intentarlo!
Conclusión
- Octoparse es una herramienta de web scraping que ofrece un plan gratuito para los usuarios. Está especialmente diseñado para el uso de personas que no saben codificar. ¡La mejor herramienta para comenzar tu proyecto de web scraping desde cero!
- Puedes utilizar la función de detección automática en Octoparse para obtener datos de cualquier sitio web. Esto te liberará de los confusos pasos de construcción del raspador a los que probablemente se enfrente en otras herramientas.
- ¡No es necesario escribir código para modificar Xpath! Apuntar y hacer clic es la forma más amigable de enseñarle al robot lo que debe hacer.
- “¿Cuánto tiempo llevará extraer más de 2000 URLs de imágenes?”
“5 minutos.”



