El web scraping es una técnica popular para extraer datos de sitios web. Implica el uso de herramientas de software para recopilar datos de páginas web y almacenarlos para su uso posterior. cURL es uno de los rastreadores web más utilizados. Sus puntos fuertes son tales que sigue siendo elegido y utilizado por muchos programadores hoy en día, pero también tiene sus puntos débiles y si un raspador de datos sin código sería una opción mejor y más popular que su código.
En este artículo, te explicaremos qué puede hacer cURL y cómo utilizarlo para la recopilación de datos, además de explorar los beneficios potenciales de un recopilador de datos automatizado para tus necesidades de rastreo web personalizado. Ahora empecemos.
¿Qué es cURL y por qué se utiliza?
cURL significa client-side URL (URL del lado del cliente) y es una herramienta de línea de comandos de código abierto que permite a los usuarios transferir datos hacia y desde servidores web utilizando diversos protocolos de red (por ejemplo, HTTP, HTTPS, FTP, etc.).
Al proporcionar una interfaz de línea de comandos, permite a los usuarios recopilar fácilmente datos de sitios web. Se utiliza ampliamente para tareas como interacciones con API y descargas o cargas remotas de archivos.
Comandos básicos de cURL
A continuación, cubriremos algunos comandos básicos para ayudarte a empezar. Para obtener una lista más completa de opciones y funciones, puede consultar el sitio de DOC. de cURL.
Recuperación de páginas web
El comando cURL más básico consiste en enviar una petición HTTP GET a una URL de destino y mostrar la página web completa (incluido su contenido HTML), que se visualiza en una ventana de terminal o símbolo del sistema. Para ello, basta con escribir curl y, a continuación, la URL de destino (tenga en cuenta que aquí se requiere la dirección de enlace completa de los datos):
Guardar contenido web en un archivo
cURL también puede utilizarse para descargar archivos de un servidor web. Para guardar el contenido de una página web en un archivo en lugar de mostrarlo en una ventana de ejecución de comandos, utilice la directiva -o o –output seguida del nombre del archivo:
Este comando guarda el contenido de la página web en un archivo llamado output.html en el directorio de trabajo actual. Si está trabajando con archivos, utilice el comando -O (o –remote-name), que escribirá la salida en un archivo llamado remote-file.
Estos comandos básicos de cURL pueden ayudarte a empezar. Sin embargo, cURL tiene muchas más funciones y opciones avanzadas que pueden utilizarse para realizar tareas más complejas.
¿Cómo instalar cURL?
El primer paso para utilizar cURL para el web scraping es instalarlo en su sistema. cURL está disponible para los sistemas operativos Windows, Mac y Linux, puede descargar la versión adecuada de cURL para su sistema operativo desde el sitio web oficial.
A) Windows
Si utiliza Windows 10 o posterior, cURL está preinstalado. Para verificar su instalación, simplemente ejecute el siguiente comando para recibir los detalles de la versión de cURL:
B)Mac
El sistema operativo de Mac viene con la herramienta, pero homebrew la instala utilizando el siguiente código si quieres la última versión:
C) Linux
Abra una ventana de símbolo del sistema e introduzca los siguientes comandos para instalar:
¿Cómo hacer Web Scraping con cURL?
El primer paso en el uso de CURL para el scraping web es instalarlo en su sistema, ya hemos mencionado el método de instalación de curl anteriormente.
1. Determinar qué sitios web que desea rastrear
Después de instalar CURL, el siguiente paso es identificar los sitios web que desea rastrear. Es crucial elegir sitios que permitan el rastreo de páginas web, ya que algunos sitios tienen medidas anti rastreo. También es importante asegurarse de que su actividad de rastreo cumple las leyes y normativas locales.
2. Escribir el código cURL
El siguiente paso es escribir el código cURL para extraer los datos del sitio web, lo que depende de la estructura del sitio web y de los datos que se vayan a extraer. Por lo general, el código cURL contendrá los siguientes elementos:
- El método HTTP URL (GET o POST) del sitio web que desea rastrear.
- La cabecera contenida en la solicitud
- Los datos contenidos en la solicitud (si procede)
- El formato de salida (por ejemplo, JSON o CSV)
3. Ejecución del código cURL
Después de escribir el código cURL, el siguiente paso es ejecutarlo. Para ello, abra la interfaz de línea de comandos y vaya al directorio donde está almacenado el código CURL. A continuación, escriba el siguiente comando:
En este ejemplo, el código CURL envía una solicitud GET a la URL especificada y guarda el resultado en un archivo CSV llamado output.csv. El código también contiene una cabecera que especifica que la salida está en formato JSON.
Ventajas del Curl Web Scraping
Respuesta rápidas
CURL es una herramienta de línea de comandos diseñada para ser rápida y eficiente, ideal para el rastreo web. Puede gestionar varias peticiones simultáneamente, lo que le permite extraer datos de varias páginas web a la vez. Esta velocidad y eficacia hacen de CURL una excelente opción para tareas de rastreo web que requieren la extracción de grandes cantidades de datos.
Gran flexibilidad
CURL es una herramienta muy flexible que puede personalizarse para diferentes necesidades de rastreo web. Es compatible con una amplia gama de protocolos, como HTTP, FTP, SMTP y POP3. Esta flexibilidad permite integrar fácilmente CURL en diversos flujos de trabajo de rastreo web, en función de los requisitos específicos del proyecto.
Además, CURL puede integrarse fácilmente en lenguajes de programación como Python, PHP y Ruby, lo que lo convierte en una herramienta de rastreo web aún más versátil.
Gran seguridad de los datos
CURL es compatible con una serie de protocolos de seguridad, como SSL y TLS, que garantizan la transferencia segura de datos entre servidores. Esto es especialmente importante cuando se rastrea información confidencial, como datos financieros o información personal, y la función de transferencia segura de datos de CURL ayuda a proteger la privacidad de los datos y a evitar su filtración.
Desventajas del Curl Web Scraping
Interfaz compleja y larga curva de aprendizaje
CURL es una herramienta de línea de comandos, lo que significa que los usuarios deben estar familiarizados con los conceptos básicos de la interfaz de línea de comandos para utilizarla con eficacia. Esto puede ser una desventaja para quienes no están acostumbrados a trabajar en un entorno de línea de comandos.
CURL es difícil de aprender, especialmente para los principiantes. La herramienta tiene varios parámetros y opciones que deben configurarse correctamente para garantizar un rastreo eficaz de las páginas web. Además, la documentación de CURL es difícil de entender, lo que dificulta la iniciación de los principiantes.
Capacidades limitadas de rastreo web
En comparación con otros rastreadores web, las capacidades de rastreo web de CURL son relativamente básicas. Aunque CURL puede extraer datos de páginas HTML, no tiene capacidad integrada para analizar datos estructurados como JSON o XML. Esta limitación dificulta el rastreo de determinados tipos de sitios web.
Encendido la potencia de scraping con Octoparse
Entre las muchas técnicas de rastreo de datos, curl no es la opción óptima en ningún caso. Las herramientas de scraper de páginas están cada vez más automatizadas y pueden ser más flexibles a la hora de reconocer distintos tipos de sitios web y scrapear todo tipo de datos:
Manipulación sencilla de páginas
Octoparse navegador incorporado puede soportar apuntar y hacer clic en el tipo de datos que desea , de acuerdo con la operación Consejos , usted puede fácilmente lograr el cambio de página automática y la carga desplegable , no es necesario un conocimiento básico de programación puede aprender a crear el flujo de trabajo.

Scraping dinámica de páginas
En la captura de páginas web, a menudo nos encontramos con cambios dinámicos en la página, especialmente el tipo de comercio electrónico de sitio web. Para hacer frente a este tipo de recopilación del sitio, con la identificación automática de la estructura del sitio de software de scraper de datos mostrará su papel. función Auto-detectar de Octoparse puede satisfacer todos los tipos básicos de la identificación de la estructura del sitio y la extracción.
https://www.octoparse.es/template/mercadolibre-detalles-scraper
Antibloqueo
Normalmente, la recopilación de páginas web se ve limitada porque el sitio reconoce que la persona que realiza estas operaciones es un robot. Octoparse resuelve este problema simulando el comportamiento de recopilación humano y esperando antes de actuar (AJAX). Al mismo tiempo, también proporciona a los usuarios la función de proxy de IP, que rota automáticamente la IP cuando la página web está restringida al comportamiento de recogida, con el fin de garantizar el buen funcionamiento del proceso de recogida.
Ejecutar en la nube
Debido a la limitación de los equipos existentes, la velocidad y el volumen de datos de la captura se verán afectados. Por lo tanto, Octoparse proporciona una solución de captura en la nube, que permite a los usuarios lograr una rápida captura de datos y su transmisión en tiempo real a la base de datos sin tener en cuenta las condiciones de los equipos existentes.
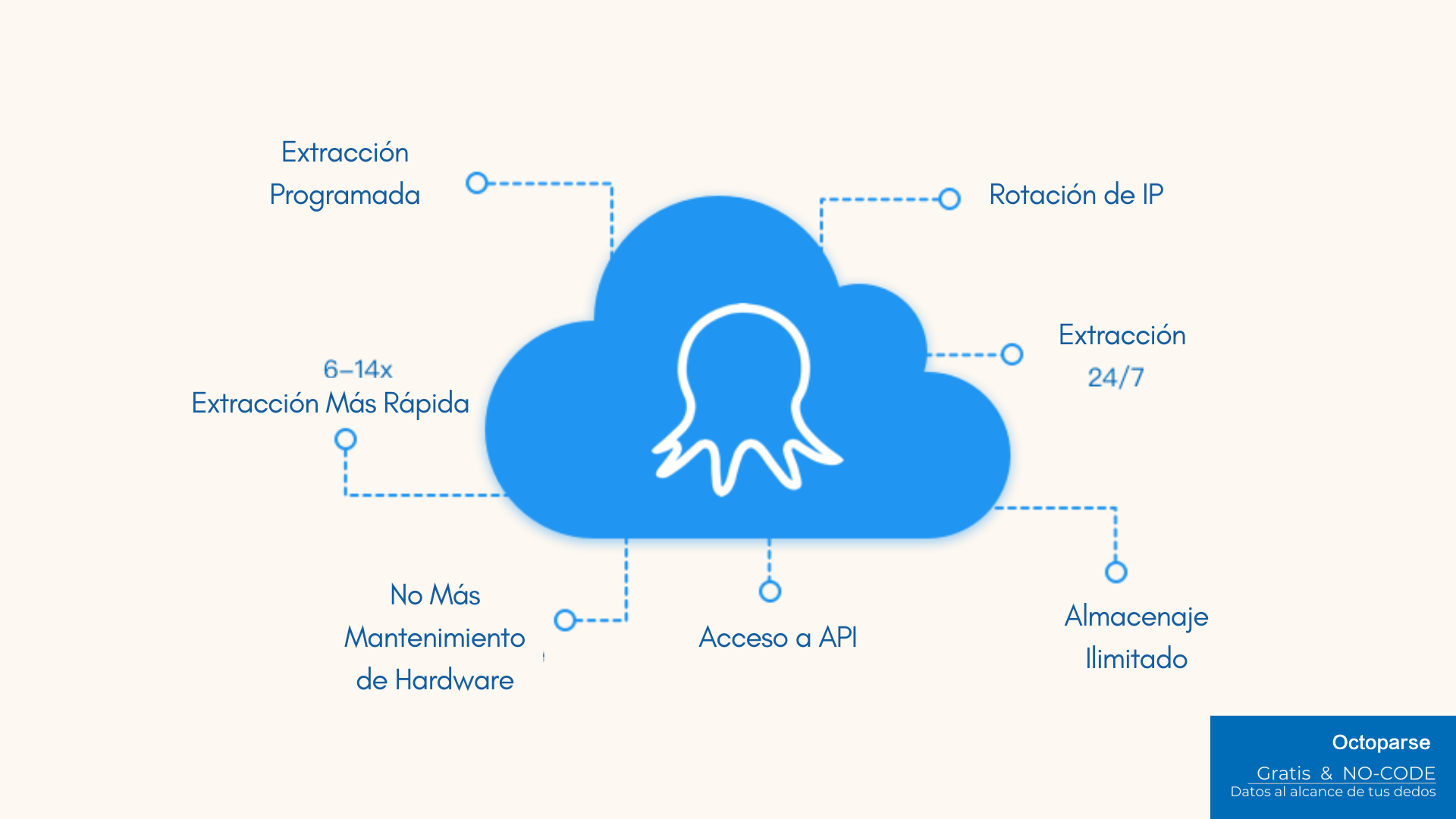
Conclusión
El web scraping es una técnica importante para extraer datos de páginas web con el fin de satisfacer una amplia gama de necesidades. cURL es la herramienta clásica de rastreo que todavía se utiliza ampliamente por sus potentes características, pero su complejidad hace que los recolectores sin código sean una opción más popular.
Elegir una herramienta que se adapte mejor al tipo de página web y a las necesidades individuales de los datos es la única forma de ser más productivo. Si aún no está seguro de qué método debe elegir para capturar sus datos, póngase en contacto con nosotros para recibir un asesoramiento más profesional.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



