El experto en datos de Octoparse te compartirá con información útil sobre Octoparse. Comenzamos con cómo Octoparse resuelve los problemas más comunes en el web scraping.
Problemas más comunes en el raspado de datos
¿Qué sucede si extraes demasiados datos de un sitio web y bloquea tu IP local?
Esto puede ser frustrante, ya que una vez que el sitio web te bloquea, no solo no te permite eliminarlo, ni siquiera puedes acceder a él para una visualización normal.
¿Qué harás si esto sucede? Al final, es posible que tengas que pagar por un proxy para intentar pasar eso.
¿Cómo protege Octoparse tu IP local? Tenemos Cloud Extraction, que ejecuta tus tareas las 24 horas del día, los 7 días de la semana. Las tareas se ejecutarán en nuestros servidores en la nube, utilizando nuestras direcciones IP en la nube. De esta forma, tu IP local es muy segura. Nuestra nube incluye cientos de direcciones IP diferentes para ayudar a reducir la posibilidad de ser bloqueado.
¿Qué sucede si deseas una gran cantidad de datos pero el scraping local tarda una eternidad en obtener los datos?
Todos quieren más datos, ¿verdad? Mientras más, mejor. Pero raspando localmente, la velocidad es bastante limitada. Depende en gran medida del rendimiento de tu dispositivo y de las condiciones de la red. Ocupa la memoria de la computadora, lo que puede afectar a otros programas de trabajo.
¿Cómo ayuda la extracción en la nube con eso? Como mencionamos anteriormente, la extracción en la nube se basa en nuestros servidores en la nube. Eso lanzará tus dispositivos locales. Simplemente haz clic en el botón de inicio de ejecución y podrás dejarlo allí. Apagar el software o incluso tu dispositivo está bien.
Y en la nube, tu tarea se dividirá en subtareas. Habrá varias subtareas ejecutándose al mismo tiempo para acelerar. Cuanto mayor sea el plan que tengas, más servidores en la nube obtendrás, más rápido se ejecutarán tus tareas.
¿Qué sucede si deseas actualizar el precio del producto cada día?
¿Alguno de vosotros recopila datos de precios de comercio electrónico? ¿Inicias la tarea manualmente todos los días cuando enciendes la computadora? Eso podría llevar mucho tiempo. Y una vez que te olvidas de hacerlo, pierdes los datos de un día. ¡Muy triste!
¡La extracción programada de Octoparse está diseñada para resolver esto! Tienes diferentes intervalos para elegir. Diariamente, semanalmente mensualmente e incluso para raspar cada 5-30 minutos. Simplemente configúralo y siéntate a esperar a que se recopilan los datos. ¡Increíble verdad!
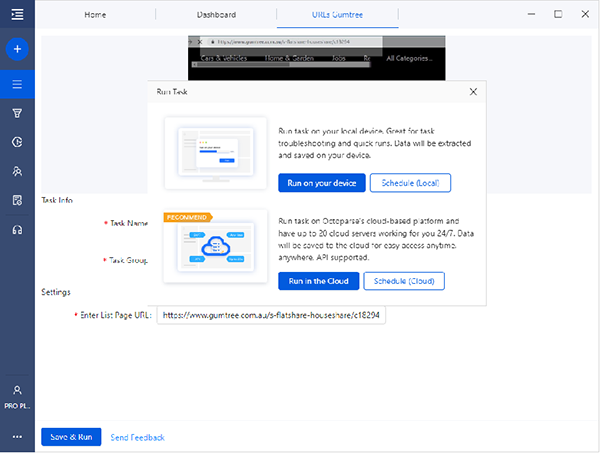
También hemos agregado una nueva característica: el horario local. El horario no es solo una cuestión de nube ahora. Si tienes sitios web a los que debe acceder dentro de tu propio entorno de red, puedes programarlos para que se ejecuten todos los días en tu dispositivo. Pero recuerda no encender tu computadora y, por supuesto, Octoparse.
Tienes muchos sitios web para rastrear y se necesita mucho tiempo para crear las tareas
Supongo que muchos de vosotros no necesitáis raspar ni un sitio web. Y la mayoría de los sitios web de destino son los mejores, ¿verdad? ¡Lo sabemos! Octoparse es famoso por su interfaz fácil de usar. Puedes crear una tarea en cuestión de minutos con puntos y clics. Y nuestra nueva detección-automática puede ayudar a acelerar el proceso de creación mucho más. Pero tenemos algo mejor.
¡Y hemos preparado más de cien plantillas prediseñadas para ti! Esto es increíble. ¡Mira todas estas plantillas! Debe haber uno que necesites.
Solo necesitas escribir los parámetros e iniciarlo. No necesitas crear nada, pero tienes todo a mano.
Algunas características útiles de Octoparsee
Espera antes del tiempo
¿Alguno de vosotros lo has usado en tus tareas? Esta función se puede configurar para cualquier acción en el flujo de trabajo de tu tarea para ayudar a cargar la página o ayudar a ralentizar tu raspado. Muchos sitios web te bloquean cuando accedes a ellos con demasiada frecuencia. Por lo tanto, esta función te ayudará a reducir la posibilidad de ser bloqueado.
Y para hacer que el raspado sea más humano, tenemos una opción aleatoria, lo que significa que esperará aleatoriamente en diferentes páginas.
Otra característica que funciona para anti-scraping, es el navegador de rotación automática y las cookies de borrado-automático.
Ve a la configuración de la tarea y podrás encontrarla. El navegador de rotación automática está girando el UA, que es una cadena para indicarle al sitio web de destino con qué tipo de dispositivo estás accediendo a la página. Cambiar la UA puede ayudarnos a fingir que estamos accediendo a la página en diferentes navegadores.
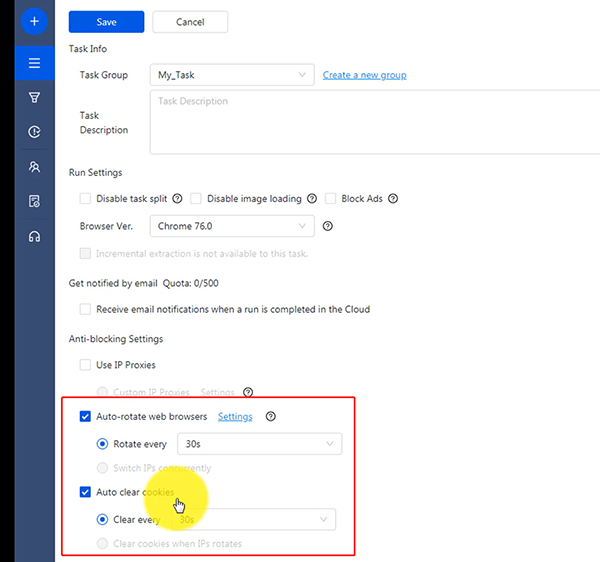
Cuando navegas por una página, guarda cookies, que incluyen tu información de inicio de sesión, información de la computadora o información de la red. Cuando se raspa un sitio web de manera consistente con las mismas cookies, es fácil de detectar como una actividad de bot de raspado. Octoparse borrará las cookies de vez en cuando para pretender ser la primera vez que accede a la página web con esta función.
Triggers
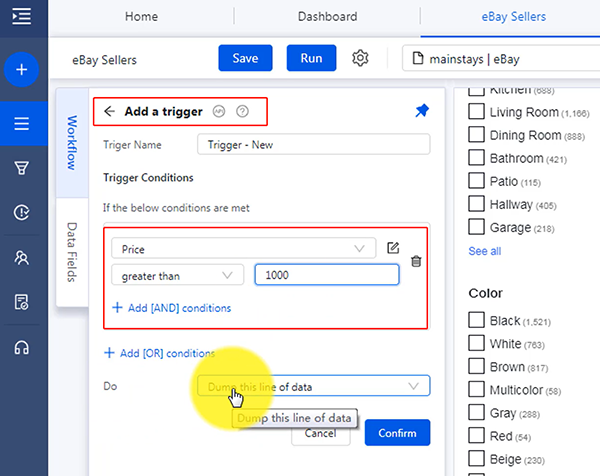
Parece algo técnico, pero Trigger puede verse simplemente como un filtro de datos. Por ejemplo, cuando raspas en un sitio web de comercio electrónico, solo deseas obtener productos cuyos precios estén por debajo de los 1000 dólares. Puedes raspar todos los datos y filtrarlos según la columna de precios. Con Trigger, no necesitarás filtrar después de que se raspan los datos. Puedes usar Trigger para configurar una condición como cuando el precio es mayor que 1000, volcar la línea. O cuando raspas las noticias, solo quieres que se publiquen las noticias hoy, puedes configurar un disparador para finalizar el raspado cuando la fecha de publicación sea anterior a hoy.
Esto podría ayudarte a ahorrar tiempo en la limpieza de datos.
Extracción incremental
Los sitios web, como los portales o foros de noticias, suelen tener contenido nuevo agregado rápidamente. Para mantenerse actualizado con dichos sitios web, la extracción incremental de Octoparse te permite extraer datos actualizados de manera mucho más efectiva al omitir las páginas que ya se han extraído, en otras palabras, solo raspar las nuevas.
Extracción incremental verificará si una URL ha sido raspada o no y la saltará si ha sido desechada. Por lo que ahorra mucho tiempo para el raspado.