Amazon es una de las principales plataformas de comercio electrónico con una amplia gama de productos para satisfacer casi todas las necesidades de las personas en su vida diaria. Los innumerables listados de productos la convierten en una mina de enormes datos. Los propietarios de tiendas online suelen extraer datos de Amazon como referencia para rastrear a la competencia, mejorar las estrategias comerciales y comprender las tendencias del mercado.
Como sabemos, Python es el lenguaje de programación más común y popular para el web scraping, que permite a los rastreadores capturar datos de sitios web. Así que hay muchos propietarios de tiendas online que están acostumbrados a utilizar Python para scrapear datos de Amazon. Sin embargo, es difícil de implementar y lleva mucho tiempo para aquellos que no tienen conocimientos básicos de codificación. Entonces, elegir aquellas herramientas de web scraping que no requieran codificación sería una mejor opción.
Este artículo le enseñará cómo usar Python para raspar datos de Amazon y recopilar datos más fácilmente con herramientas de web scraping sin codificación.
¿Qué es Python?
Para los que no hayan tocado Python o no tengan ninguna base de programación, merece la pena detenerse aquí un momento: Python es un lenguaje de programación relativamente antiguo, pero sigue funcionando perfectamente para determinadas tareas (como el análisis de datos). Esto se debe al enorme número de bibliotecas adicionales que han escrito los programadores a lo largo de los años, y a la enorme ventaja que tenemos de poder utilizarlas gratuitamente.
¿Cómo scrapear datos de Amazon con Python?
En la actualidad, muchos marcos de trabajo web están escritos en Python, lo que lo convierte en un lenguaje de programación muy utilizado para el web scraping. Y hay muchos Amazon sellers quieren obtener datos por API Python. Muchas bibliotecas de Python (como BeautifulSoup y Selenium) facilitan el análisis sintáctico de HEML y el raspado de sitios web dinámicos, y se pueden utilizar para automatizar tareas y procesos de raspado mediante scripts. A continuación daré un ejemplo de esto.
Pasos para extraer datos de Amazon con Python
Paso 1: Instala la librería Requests para obtener el contenido HTML, y BeautifulSoup para analizar el contenido HTML.
Paso 2: Utiliza la librería Requests para enviar una petición GET a la página de Amazon que quieras scrapear. Entonces obtendrás el HTML de la página.
Paso 3: Pasa el HTML a BeautifulSoup para crear un objeto soup. Te permitirá analizar el HTML.
Paso 4: Encuentra los datos que quieres extraer del HTML. Para los productos de Amazon, es posible que necesite títulos de productos, descripciones, precios, calificaciones, recuentos de revisión, etc.
Paso 5: Extraer el texto y los atributos de los elementos HTML con BeautifulSoup.
Paso 6: Almacenar los datos extraídos en una estructura de datos como una lista, diccionario, o Pandas DataFrame.
A continuación se muestra un ejemplo de cómo extraer los títulos de los productos de Amazon de una página utilizando BeautifulSoup:
El flujo de trabajo de Amazon Finder es enviar una petición GET a la página de Amazon Laptop Search y obtener el contenido HTML. A continuación, se analiza utilizando BeautifulSoup y se extraen los títulos de los productos utilizando un selector CSS.
Aunque la programación en Python es relativamente sencilla y legible en comparación con otros lenguajes, la creación de un raspador de datos de Amazon utilizando Python puede ser un reto para las personas sin experiencia en programación. Aquí es donde las herramientas de raspado de Amazon que no requieren codificación resultan útiles.
Alternativa sin codificación: Extraer los datos de Amazon con unos clics
Octoparse es una herramienta de web scraping fácil de usar que cualquiera puede utilizar independientemente de sus conocimientos de codificación. En lugar de escribir scripts, puede crear un crawler de Amazon con unos pocos clics. Además, Octoparse tiene potentes funciones que pueden ayudar a que el web scraping sea más fácil y automático.
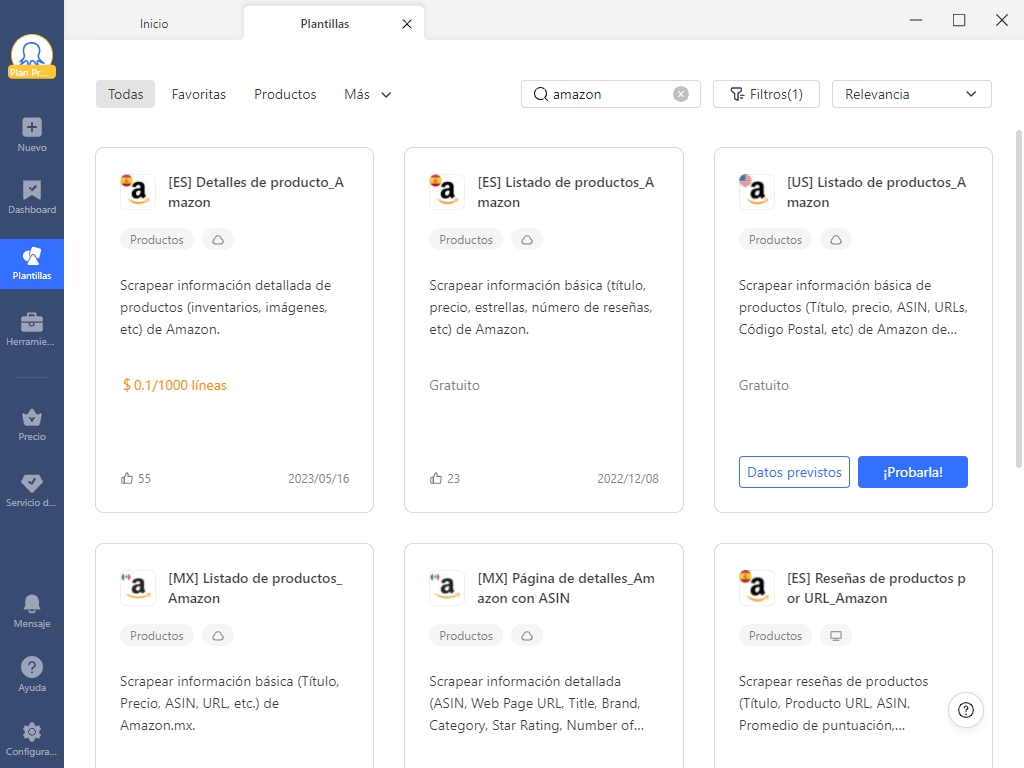
Plantillas predefinidas
Octoparse ofrece ahora más de 100 plantillas preestablecidas para la extracción de datos de sitios web concretos. Las plantillas te permiten extraer datos con cero configuraciones introduciendo un par de parámetros necesarios. En el caso de Amazon, existen varias plantillas para raspar precios, reseñas, valoraciones, etc., de diferentes regiones. Puedes buscar “Amazon” en la Galería de Plantillas de Octoparse para encontrar los scrapers que se ajusten a tus necesidades o directamente visitarlas directamente haciendo clic en los enlaces siguientes.
https://www.octoparse.es/template/amazon-espana-listados-scraper
https://www.octoparse.es/template/amazon-mexico-asin-scraper
Detección automática de datos de páginas web
Sin embargo, es posible que tenga necesidades más específicas, por lo que necesitará un rastreador personalizado. En Octoparse, la construcción de un scraper se simplifica en varios pasos. Puede crear una tarea para rastrear detalles de productos, reseñas, precios, etc., con sólo unos clics en lugar de escribir scripts.
La detección automática es la característica clave para que la creación de raspadores sea más fácil y sin esfuerzo. Esta función permite a Octoparse escanear la página y detectar automáticamente los datos extraíbles. Así, los usuarios pueden obtener los campos de datos deseados en cuestión de segundos sin tener que molestarse en leer archivos HTML y datos locales a mano.
Lectura relacionada:
Cómo Scrapear Datos de Productos de Amazon
Data scraping en Amazon sin codificación en 5 minutos
Ejecución programada y exportación automática de datos
Los datos de los productos de Amazon cambian constantemente. Obtener información actualizada sobre Amazon puede ayudarle a mantenerse por delante de sus competidores. Contribuye a estrategias de precios competitivas, estudios de mercado perspicaces, análisis de sentimiento en profundidad, etc. Octoparse ofrece raspadores de horarios y exportación automática de datos para ayudarte a vigilar a sus competidores y el mercado en todo momento.
Con estas funciones, puede configurar un raspador de Amazon de una sola vez y programarlo para que extraiga los datos más recientes de páginas web semanal, diaria o incluso cada hora, y exportar los datos raspados a bases de datos o como archivos locales de forma automática.
Lectura relacionada:
7 Razones por Scraping Amazon
Servidores en la Nube
Octoparse está equipado con una plataforma en la nube que puede maximizar la eficiencia del scraping. Los servidores en la nube pueden procesar tareas de scraping 24/7 a un ritmo más rápido. Cuando las tareas se ejecutan en la nube, no hay limitaciones de hardware. Durante la operación, puede apagar la aplicación incluso sus ordenadores sin perder una fila.
Construir raspadores de Amazon con características tan potentes sólo necesita varios clics en Octoparse. Incluso puede explorar más con XPath, expresiones regulares, acceso API, proxies IP, etc., para mejorar la eficiencia de los scrapers. Para probar todas estas funciones, descarga Octoparse de forma gratuita y disfruta de 14 días de prueba.
Pensamientos Finales
Aprovechando el poder de Python y bibliotecas como BeautifulSoup y Selenium puede desbloquear valiosos datos de Amazon para analizar y obtener información procesable. Esta técnica requiere algunos conocimientos de codificación y experiencia, y la estructura HTML de las páginas puede romper el raspador.
Si está buscando una alternativa más fácil y cómoda, Octoparse debería estar en su lista. No necesita conocimientos de codificación y proporciona una solución para el raspado web automático. Además de estas opciones, también puede consultar la lista de los mejores raspadores de Amazon para encontrar uno que pueda satisfacer el 100% de sus necesidades.