Data mining (exploración de datos o minería de datos) consiste en extraer información válida de conjuntos de datos gigantes y transformar la información en patrones potencialmente útiles, en última instancia, comprensibles para su uso posterior. No solo incluye el procesamiento y la gestión de datos, sino que también involucra los métodos de inteligencia del aprendizaje automático, las estadísticas y los sistemas de bases de datos, como lo define Wikipedia.
¿Por qué es importante la minería de datos?
¿Entonces por qué es importante la minería de datos? Ha podido apreciar los números asombrosos – el volumen de datos producidos se duplica cada dos años. Los datos no estructurados por sí solos conforman el 90% del universo digital. Pero más información no significa necesariamente más conocimientos.
La minería de datos te permite:
- Filtrar todo el ruido caótico y repetitivo en tus datos.
- Entender qué es relevante y luego hacer un buen uso de esa información para evaluar resultados probables.
- Acelerar el ritmo de la toma de decisiones informadas.
Aprende más acerca de técnicas de minería de datos en Minería de datos de la A a la Z, documento que muestra cómo pueden las organizaciones utilizar la analítica predictiva y la minería de datos para revelar nuevos insights partiendo de datos.
Para ayudar a nuestra audiencia a dominar la tecnología de la ciencia de datos, publicamos 80 Mejores libros de ciencia de datos que son dignos de leer y 88 Recursos & herramientas para convertirse en un científico de datos. En este artículo, me enfocaré en el campo de la minería de datos y resumiré 10 habilidades esenciales que necesita.
Habilidades de Informática Ciencia
1. Lenguaje de programación/estadística: R, Python, C++, Java, Matlab, SQL, SAS, shell/awk/sed…
Data mining depende en gran medida de la programación, sin embargo, no hay una conclusión sobre cuál es el mejor lenguaje para la data mining. Todo depende del conjunto de datos con el que trates. Peter Gleeson presentó cuatro espectros para su referencia: Specificity, Generality, Productivity, and Performance. Se pueden ver como un par de ejes (Specificity- Generality, Performance – Productivity). La mayoría de los idiomas pueden caer en algún lugar del mapa. R y Python son los lenguajes de programación más populares para la ciencia de datos, según una investigación de KD Nuggets.
Más recursos:
¿Qué Idiomas Debe Aprender para La Ciencia de Datos [Freecode Camp]
Algoritmos de Data Mining en R [Wikibooks]
Los Mejores Módulos de Python para Data Mining [KD Nuggets]
2. Big data procesamiento de datos: Hadoop, Storm, Samza, Spark, Flink
Los marcos de procesamiento computan sobre los datos en el sistema, como leer del almacenamiento no volátil e ingerir datos en su sistema de datos. Este es el proceso de extracción de información y conocimientos de grandes cantidades de puntos de datos individuales. Se puede clasificar en 3 clasificaciones: batch-only, stream-only and hybrid.
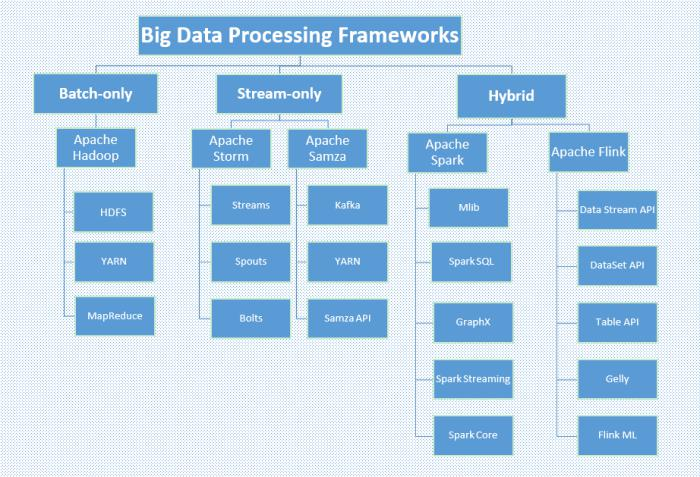
Hadoop y Spark son los frameworks más implementados hasta ahora, ya que Hadoop es una buena opción para cargas de trabajo por lotes que no dependen del tiempo, lo cual es menos costoso de implementar que otros. Considerando que, Spark es una buena opción para cargas de trabajo mixtas, ya que proporciona procesamiento por lotes de mayor velocidad y procesamiento por micro lotes para transmisiones.
Más recursos:
Hadoop, Storm, Samza, Spark y Flink: Frameworks de Big Data Comparados Océano Digital]
Frameworks de Procesamiento de Datos para Minería de Datos [Google Scholar]
3. Sistema Operativo: Linux
Linux es un sistema operativo popular para los científicos de minería de datos, que es mucho más estable y eficiente para operar grandes conjuntos de datos. Es una ventaja si conoce los comandos comunes de Linux y puede implementar un sistema de aprendizaje automático distribuido de Spark en Linux.
4. Conocimiento de Database: Database Relacionales & Database Non-Relacionales
Para administrar y procesar grandes conjuntos de datos, debe tener conocimiento de bases de datos relacionales, como SQL u Oracle. O necesita conocer Database Non-Relacionales, cuyos tipos principales son: Column: Cassandra, HBase; Document: MongoDB, CouchDB; Key value: Redis, Dynamo.
Estadísticas & Habilidades de Algoritmo
5. Conocimientos Básicos de Estadística: Probabilidad, Distribución de probabilidad, Correlación, Regresión, Álgebra Lineal, Proceso Estocástico…
Recordando la definición de data mining al principio, sabemos que data mining no se trata solo de codificación o informática. Se encuentra en las interfaces entre múltiples campos, entre los cuales las estadísticas son una parte integral. El conocimiento básico de las estadísticas es vital para un minero de datos, lo que le ayuda a identificar preguntas, obtener una conclusión más precisa, distinguir entre causalidad y correlación, y cuantificar la certeza de sus hallazgos también.
Más recursos:
Qué estadísticas debo saber para hacer ciencia de datos [Quora]
Métodos estadísticos para Data Mining [Research Gate]
6. Estructura de Datos & Algoritmos
Las Estructuras de Datos incluyen matrices, lista vinculada, pilas, colas, árboles, tabla hash, conjunto … etc., y los algoritmos comunes incluyen clasificación, búsqueda, programación dinámica, recursividad … etc.El dominio de las estructuras y algoritmos de datos es de gran utilidad para la data mining, lo que le permite encontrar soluciones algorítmicas más creativas y eficientes al procesar grandes volúmenes de datos.
Más recursos:
Datos, Sstructura y la Data Science Pipeline [IBM Developer]
Cousera: Estructuras de Datos y Algoritmos [UNIVERSITY OF CALIFORNIA SAN DIEGO]
7. Algoritmo de Aprendizaje Automático/Aprendizaje Profundo
Esta es una de las partes más importantes de la minería de datos. Los algoritmos de aprendizaje automático crean un modelo matemático de datos de muestra para hacer predicciones o decisiones sin ser programado explícitamente para realizar la tarea. Y el aprendizaje profundo es parte de una familia más amplia de métodos de aprendizaje automático. El aprendizaje automático y data mining a menudo emplean los mismos métodos y se superponen significativamente.
Más recursos:
Fundamentos de los Algoritmos de Aprendizaje Automático con Python y Códigos R [Analytics Vidhya]
Una Lista Curada de Impresionantes Frameworks, Bibliotecas y Software de Aprendizaje Automático (por idioma)[Github josephmisiti]
8. Procesamiento de Lenguaje Natural
El Procesamiento del Lenguaje Natural (NLP), como un subcampo de la informática y la inteligencia artificial, ayuda a las computadoras a comprender, interpretar y manipular el lenguaje humano. NLP es ampliamente utilizado para la segmentación de palabras, la sintaxis y el análisis semántico, el resumen automático y la implicación textual. Para los data miners que necesitan lidiar con una gran cantidad de texto, es una habilidad imprescindible conocer los algoritmos de NLP.
Más recursos:
10 Tareas de NLP para Científicos de Datos [Analytics Vidhya]
Una lista curada de impresionantes marcos, bibliotecas y software de aprendizaje automático (por idioma) [Github josephmisiti]
Bibliotecas NLP de Código Abierto: Standford NLP; Apache OpenNLP; Naturel Language Toolkit
Otras habilidades externas
9. Experiencia en proyectos
Su experiencia en el proyecto es la prueba más provincial de sus habilidades de data mining. Cuando se le preguntó cómo conseguir el primer trabajo de ciencia de datos, David Robinson, el científico jefe de datos en DataCamp, dijo: “La estrategia más efectiva para mí fue hacer trabajo público. Escribí en un blog e hice mucho desarrollo de código abierto tarde en mi Ph .D., Y esto ayudó a dar evidencia pública de mis habilidades de ciencia de datos “. Si desea obtener más experiencia en data mining, intente encontrar los mejores proyectos en las 12 plataformas de programas de ciencia de datos más populares.
10. Habilidades de Comunicación & Presentación
Data miners no solo se ocupan de los datos, sino que también son responsables de explicar los resultados y las ideas extraídas de los datos a otros. A veces necesitan explicárselos a audiencias no técnicas, como el equipo de marketing. Nesecita analizar bien los resultados de los datos en forma oral, escrita y de presentación.
Conclusión
Si formas parte del área de Marketing y Comunicación de tu empresa y quieres desarrollarte como experto en data mining para establecer estrategias efectivas, ve a dominar estas 10 habilidades para data mining, que ayudará mucho en tu negocio o trabajo.
Si buscas una manera que puede realizar data mining sin estos conocimiento, podrías utilizar herramientas de data mining como Octoparse, Octoparse proporciona todo lo que necesitas para la extracción automática de datos. Puedes scrapear los datos web rápidamente sin codificar y convierte las páginas web en datos estructurados con clics.



