Existen muchas herramientas de web scraping, como las famosas bibliotecas de Python Beautiful Soup, lxml, parsel, etc. La mayoría de los científicos de datos y desarrolladores, sin embargo, probablemente nombren a Scrapy como la herramienta que goza de mayor popularidad de todas ellas.
Sigue leyendo, y aprenderás más sobre Scrapy web scraping también sus alternativas y cuándo debes utilizar qué herramienta para extraer datos en función de tus necesidades y habilidades.
¿Qué es Scrapy web scraping?
Scrapy es un framework de crawler y raspado web rápido y de alto nivel para Python. Es de código abierto y permite scrapear sitios web de forma rápida y sencilla. También puede descargar, analizar y almacenar datos raspados en tus dispositivos.
Scrapy tiene una potente capacidad para enviar peticiones asíncronas. Esto significa que puedes recopilar datos de varias páginas a la vez. Además, ofrece selectores CSS y XPath para elegir las categorías de datos que se desean extraer. Según el tutorial de Scrapy, puedes construir un spider tú mismo en 5 sencillos pasos.
Pros y contras de Scrapy
Scrapy es bien aceptado por muchos usuarios que lo consideran como uno de los mejores rastreadores web debido a sus puntos fuertes en un marco todo-en-uno, la flexibilidad en las extensiones, y la capacidad de post-procesamiento de datos.
Un Marco Completo
Si buscas en Google “web scraping Python“, obtendrás una lista de resultados. En comparación con las bibliotecas de Python, como Beautiful Soup, Scrapy proporciona un marco completo para la extracción de datos. Puedes obtener datos sin usar ninguna aplicación, programa o parser adicional. Por lo tanto, el scraping de datos utilizando Scrapy puede ser más lento y conveniente. Por el contrario, al utilizar la mayoría de las bibliotecas de Python para la recopilación de datos, es posible que necesite utilizar la biblioteca de solicitud adicional.
Flexibilidad en las extensiones
Scrapy es fácilmente extensible, lo que te permite añadir nuevas funcionalidades sin tener que tocar el núcleo. Te proporciona algunas extensiones incorporadas para propósitos generales. Por ejemplo, recibirás un e-mail de notificación cuando el scraper exceda un cierto valor con la extensión de uso de memoria. Además, la extensión cerrar araña le permite cerrar la araña automáticamente cuando se cumplan ciertas condiciones. Estas extensiones pueden mejorar tu eficacia en la extracción de datos. Por supuesto, si lo deseas, puedes escribir tu propia extensión para necesidades particulares.
Post-procesamiento de datos
Cuando visitamos un sitio web, a veces nos encontramos con que la cantidad de información disponible supera nuestras necesidades. Este problema también puede surgir al utilizar Python para raspar datos. Se pueden extraer casi todos los datos de las páginas aunque esto pueda ensuciar el archivo de datos. Lo que Scrapy opta por hacer es ofrecer una opción para activar plugins para post-procesar los datos raspados antes de exportarlos a un archivo de datos. Por ejemplo, si los datos deseados contienen comas arbitrarias, puede procesar los datos de origen en el formato que prefiera.
Sin embargo, todo tiene sus pros y sus contras. Scrapy muestra sus puntos fuertes en un framework todo-en-uno, pero no podemos ignorar que sigue siendo una herramienta de “alto nivel”. Lo que significa que no es tan fácil de usar para principiantes. Por ejemplo, su proceso de instalación es complicado. Además, sólo proporciona a los principiantes una documentación ligera. Podría ser un gran reto aprender y utilizar este programa si no tienes conocimientos previos de Python o de extracción de datos.
Alternativas a Scrapy en Python
Beautiful Soup
Beautiful Soup es una de las librerías de Python más utilizadas para el web scraping. Con esta herramienta puedes obtener elementos como una lista de imágenes o vídeos de sitios web. En comparación con Scrapy, Beautiful Soup es más fácil de usar y entender. Ofrece a los usuarios documentación útil para el aprendizaje independiente. Pero es sólo una librería de parseo con menos funcionalidad que es buena para procesar proyectos simples. Necesitarás otras librerías y dependencias si deseas usar esta librería para crear un raspador web.
lxml
Muchos desarrolladores prefieren crear sus propios analizadores en función de sus objetivos particulares. Así, lxml, una de las bibliotecas de Python más rápidas y con más funciones para procesar XML y HTML, se convierte en una buena opción para ellos. Es más potente y rápida a la hora de analizar documentos de gran tamaño y ofrece selectores CSS y XPath para localizar elementos específicos dentro de textos HTML. Con lxml, también se pueden producir documentos HTML y leer los existentes. Destaca entre muchas bibliotecas de análisis sintáctico de Python por su facilidad de programación y su rendimiento. Sin embargo, su uso también requiere conocimientos y experiencia en programación.
urllib3
Con más de 70.000.000 de descargas en PyPI a la semana, urllib3 es una popular librería Python de web scraping. Es similar a la biblioteca requests de Python y ofrece una sencilla interfaz de usuario para recuperar URLs. Puedes ejecutar cualquier petición GET y POST para analizar datos. Al igual que las herramientas mencionadas anteriormente, urllib3 requiere conocimientos de programación y tiene funciones limitadas. Para los usuarios sin experiencia en programación, puede ser un poco más difícil.
Alternativa de Scrapy para raspar cualquier páginas sin codificación
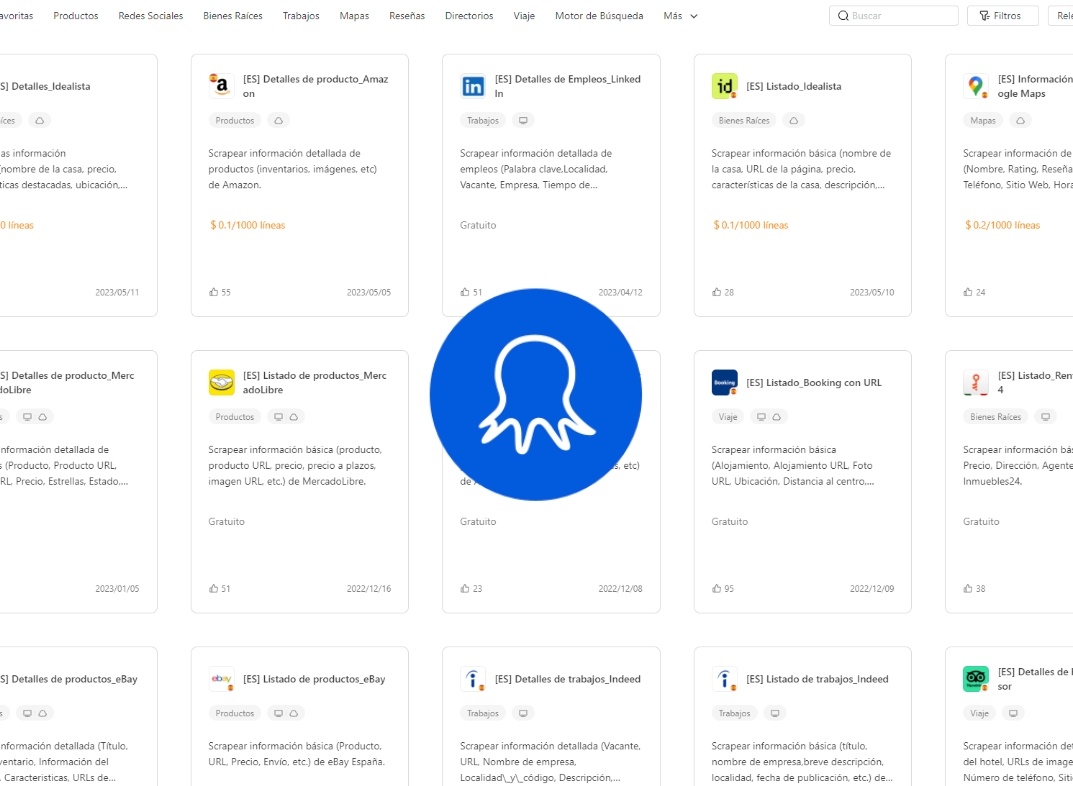
Si se ha cansado de hablar de Python o simplemente necesita una herramienta de raspado web sencilla de usar pero eficaz, Octoparse debería ser una buena opción. Octoparse es una herramienta de web scraping que no requiere codificación. Puede extraer datos con varios clics siguiendo los pasos que se indican a continuación.
Antes de comenzar su viaje de raspado de datos con Octoparse, puede descargar e instalar Octoparse en tu dispositivo. Cuando abra el software por primera vez, regístrese para obtener una cuenta gratuita e iniciar sesión.

Paso 1: Crear una nueva tarea
Si tiene una página de la que desea extraer datos, puede introducir o copiar y pegar su URL en la barra de búsqueda de Octoparse. A continuación, haga clic en “Empezar” para crear una nueva tarea y deje que la página se cargue en el navegador integrado de Octoparse.
Además de introducir manualmente las URL para crear nuevas tareas, Octoparse cuenta con una gran cantidad de plantillas de scraping que cubren todos los sitios web principales de los que desea recopilar datos. (Descubre más la galería de plantillas>>)

Paso 2: Seleccionar datos con Auto-Detectación
Espere a que la página termine de cargarse y haga clic en “Detectar automáticamente” en el panel de sugerencias. Después de escanear toda la página, Octoparse presentará una lista de posibilidades de campos de datos que pueden ser extraídos. Estos campos aparecerán resaltados en la página. También puede previsualizarlos en la parte inferior.
En este procedimiento, Octoparse puede ocasionalmente hacer una suposición “falsa”. Por ello, le proporciona varios métodos para obtener los datos deseados. Por ejemplo, puede elegir manualmente los datos haciendo clic en ellos en la página o puede utilizar XPath para localizar los datos.
Paso 3: Construir el workflow (flujo de trabajo)
Haga clic en “Crear flujo de trabajo” una vez elegidos todos los campos de datos deseados. Entonces aparecerá un flujo de trabajo en el lado derecho que describe cada etapa del scraper. Puede hacer clic en cada paso para previsualizar sus acciones y comprobar si cada paso funciona correctamente.
Paso 4: Ejecutar la tarea y exportar los datos
Compruebe todos los detalles (incluidos los campos de datos seleccionados y el flujo de trabajo) y haga clic en “Ejecutar” para iniciar el scraper. En este paso debe elegir entre ejecutar la tarea en su dispositivo local o en los servidores de la nube. Ejecute la tarea en el Could si está procesando un proyecto grande, mientras que la ejecución en su dispositivo es más adecuada para ejecuciones rápidas. Una vez finalizado el proceso de extracción, puede exportar los datos como archivo Excel, CSV o JSON.
Conclusión
Python está ampliamente aceptado entre los desarrolladores para raspar datos. Herramientas como Scrapy y bibliotecas de Python como Beautiful Soup son útiles en la extracción de datos. Son potentes, pero no son fáciles de usar para principiantes en la mayoría de las situaciones. Por el contrario, Octoparse no requiere ningún código, pero todavía tiene una potente funcionalidad para el raspado de datos.