Las expresiones XPath te ayudan a navegar fácilmente por documentos XML / HTML. Como puedes notar, el web scraping consiste en analizar documentos HTML. En este sentido, XPath es bastante útil en proyectos de raspado web, ya que te permite acceder mediante programación a elementos HTML, localizar datos y extraer datos útiles. Los selectores de CSS son una de las alternativas de XPath, pero los XPath son mucho más versátiles que los selectores de CSS cuando se trata de navegar por DOM (modelo de objetos de documento). En este blog hablaremos de:
- XPath en detalle
- Su importancia en el mundo del raspado
- Cómo encontrar XPath si no tienes conocimientos previos de XPath
- Algunos conceptos básicos de XPath, para que puedas escribir tus propios
Vamos a empezar.
¿Qué es XPath?
XPath significa lenguaje de ruta XML. Visualmente, parece un URI. Desde un ángulo conceptual, es muy similar a las instrucciones de navegación del mundo real. ¿Alguna vez te has encontrado viajando por el mundo de un lugar a otro en Google o Apple Maps? Si es así, sabrás que estas aplicaciones te indican que gires a la izquierda / derecha después de los medidores XYZ. Pero, ¿cómo instruyen las personas cuando no tienes acceso a Maps y tampoco conoces la ruta? Sus instrucciones se ven así: sigue recto y toma la primera a la izquierda después de Dominos. Mientras que las aplicaciones te dan absolutamente [toma a la izquierda después de 200 metros] rutas de navegación, las personas reales te dan una ruta de navegación relativa [toma a la derecha después de la tienda Zara]. Los XPath también son de dos tipos. ¿Puedes adivinarlos? Sí, XPath absolutos y XPath relativos.
Esa fue una introducción casual a XPath. En términos técnicos, Xpath es un lenguaje de ruta que se usa para ubicar un nodo o nodos en un archivo XML o HTML. No es complicado como un lenguaje de programación pero tiene un conjunto de reglas gramaticales para escribir rutas que atraviesan el DOM para acceder a cierto contenido en la página web.
Es especialmente útil para web scraping. Usamos Xpath para localizar datos en web scraping. Es una habilidad que debes aprender si extraes datos de páginas web. Si obtienes datos de sitios web con una estructura complicada, ¡el conocimiento de Xpath puede salvarte el día! Nada explica mejor que una experiencia práctica. Para demostrarlo y ayudarte a comprender, analizamos el DOM del sitio web de Levi’s (por ejemplo: https://www.levi.com/ES/es_ES/).
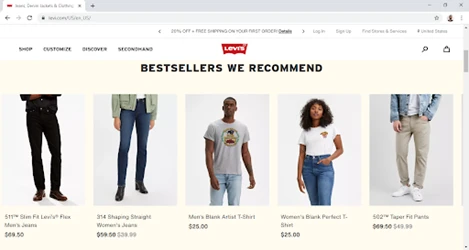
Puedes abrir esto en un navegador de tu elección: Chrome, Edge, Firefox, Safari, UC Browser, etcétera. Trae las “herramientas de desarrollo” en la pantalla. En Chrome, puedes hacer esto fácilmente presionando “Ctrl + Shift + i”, o haciendo clic con el botón derecho del ratón y seleccionando inspeccionar elemento.
Al hacerlo, aparecerá una pantalla de herramientas de desarrollo con “Elementos” como pestaña activa. Esta pestaña te muestra el código fuente de la página web activa. Puedes mover el cursor sobre las etiquetas HTML y observar las secciones resaltadas en la página web. Cada una de estas etiquetas puede considerarse un nodo y puede comprender desde cero hasta varios nodos secundarios. XPath es una sintaxis que nos ayuda a navegar a través de estos nodos HTML.
Ahora, solo para una demostración, escribiré un XPath para acceder a estos jeans recomendados en el sitio web de Levi’s. En Chrome, puedes presionar las teclas “CTRL + F” para abrir una barra de búsqueda dentro del panel de herramientas del desarrollador. Obsérvalo en la parte inferior. En Firefox, está activo de forma predeterminada en la parte superior.
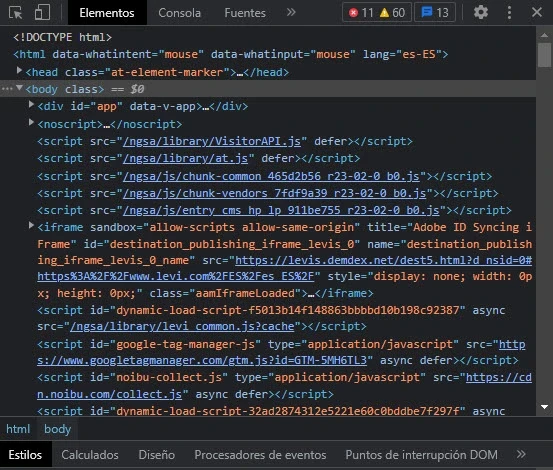
En esta barra de búsqueda, puedes escribir y validar cualquier XPath. Observa cómo se resaltó el nodo HTML para los primeros jeans recomendados cuando escribí un XPath para él en la barra de búsqueda. Al pasar el cursor sobre el nodo resaltado, también se resalta el componente HTML de Jeans en la página web.
Cómo ayuda XPath en Web Scraping
Think of a scraper as your assistant. If you want him to buy you a pack of cereal, you have to explain where it can find it clearly so that he knows exactly where to grab it: which street, in which shop, and on which shelf. Xpath is the language that works as an address. For scraping HTML documents, XPath tells your scraper:
Piensa en un raspador como tu asistente. Si quieres que te compre un paquete de cereal, tienes que explicarle claramente dónde puede encontrarlo para que sepa exactamente dónde agarrarlo: en qué calle, en qué tienda y en qué estantería. XPath es el lenguaje que funciona como dirección. Para raspar documentos HTML, XPath le dices a tu raspador:
- Qué raspar, es decir, qué datos deben extraerse
- De dónde extraer, o sea, qué nodo HTML proporcionará esos datos.
Ampliando nuestro ejemplo anterior, si necesitamos datos de precios de los 10 productos principales recomendados en la página de inicio de Levi, podemos escribir un XPath para ayudar a los analizadores de documentos a identificar los nodos HTML que contienen precios. Así es como se hace:
//div[contains(@class,”zola-carousel”)]//div[contains(@class,”price”)]
Desafíos en la localización de datos
- Digamos que necesitas recopilar datos en varias páginas y el robot repetirá el mismo conjunto de pasos en las páginas para extraer los datos. Pero el mismo elemento puede estar incrustado en diferentes estructuras en las páginas 1 y 10. En este caso, los pasos que funcionan en la página 1 pueden causar errores en la página 10.
- La cuestión es que no deseas confundir al robot ofreciéndole una dirección vaga donde se encuentra con muchos objetivos. Es muy probable que agarre el más cercano y puede que no sea el que esperabas.
Por lo tanto, escribir un XPath es sensato para dar la dirección única a un nodo que contiene tus datos de destino. El robot puede alcanzar exactamente los datos de tu interés y extraerá datos muy consistentes. Los XPath relativos escritos con los componentes que tienen menos probabilidades de cambiar, funcionarán durante un período más largo y necesitarán menos mantenimiento. Por ejemplo, yo preferiría usar contains[text(),”$”] over @class=”price” como identificadores, si ambos cumplen el propósito.
¿Por qué deberías utilizar XPath para web scraping?
Puedo anular las siguientes razones para usar XPaths para construir raspadores web robustos:
- Te ayuda a llegar a cualquier nodo visible, no visible o una colección de nodos en una página web, es decir, un documento XML. En el ejemplo de Levi’s anterior, accedimos a 10 nodos de precios, es decir, una colección que usa un solo XPath.
- Las expresiones XPath se pueden utilizar en PHP, Python, Java, Javascript, C, C ++.
- Es una norma W3C y tiene 200 funciones integradas para acceder a valores numéricos, valores booleanos, para comparar valores de fecha y hora, y también para la manipulación de nodos.
- XPath puede acceder a 7 tipos de componentes DOM: elementos o nodos HTML, atributos, espacios de nombres, comentarios, texto, instrucciones de procesamiento y nodos de documentos.
- Xpath puede atravesar una página web en cualquier dirección. También puede aprovechar las relaciones entre los nodos para navegar por el DOM, es decir, puedes escribir XPaths para encontrar padres, hermanos, descendientes, ancestros, etcétera de un nodo.
- Los XPath relativos pueden ser muy efectivos incluso si cambia la estructura del sitio web.
- Los XPaths pueden comenzar desde el nodo raíz, es decir, / o pueden comenzar desde cualquier nodo //. Tienes funciones como position (), last (), etcétera que puedes agregar como predicado y usar junto con operadores como <,>, <=, +, -, div, etcétera para acceder / extraer datos de la página web de forma selectiva.
Soluciones alternativas de Octoparse
Octoparse se compromete a hacer que Web Scraping sea más fácil, más rápido y mejor, especialmente para los que no codifican. Pueden obtener datos web como lo hacen los programadores.
- Característica de detección automática
Octoparse utiliza IA para detectar de forma inteligente datos útiles en la página web. La función se denomina función de detección automática y está disponible a partir de la versión 8 de Octoparse. La función de detección automática ha sido muy exitosa y eficaz para detectar tablas, pergaminos infinitos, cargar más, enumerar datos y varios otros paradigmas de diseño web sin necesidades de escribir xpath. Lo único que tendrás que hacer es ingresar URL en la pantalla de inicio y hacer clic en modo de detección automática para activarlo.
¡Pan comido! ¿No lo es?
- Extraer datos haciendo clic en el navegador integrado
Alternativamente, si estás utilizando la herramienta de la versión anterior de Octoparse, o si con la función de detección automática no se detectan los datos que necesitas para un sitio web (caso bastante complicado), puedes hacer clic en la página web para extraer los datos. Si deseas ver o modificar XPath, también es aceptable y la herramienta de xpath de Octoparse te podrá ayudar.
Estos son los pasos para ver / modificar XPath en la versión anterior de Octoparse:
Paso 1: Ingresar URL de donde quieres extraer datos en la página de inicio de Octoparse. Seleccionar los datos de destino y hacer clic en Extraer datos en el panel de Tips. En resumen, crea tu flujo de trabajo. Cuando los datos se seleccionen con éxito, se volverán verdes.
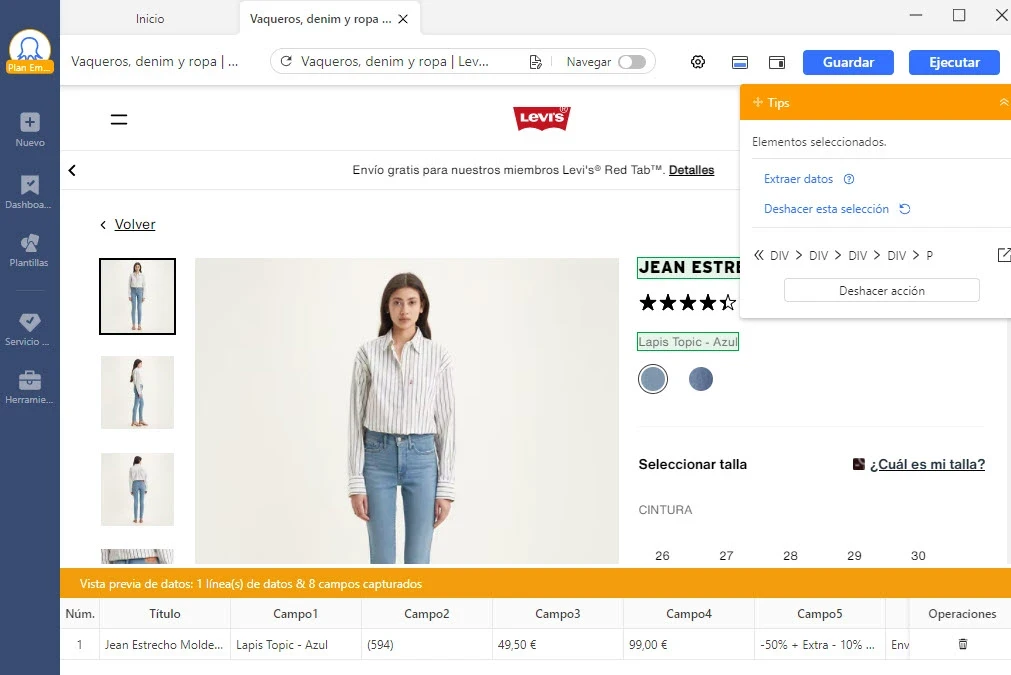
Paso 2: Al hacer clic en Extraer datos, los datos sadrán en la previa vista de datos. Puedes examinar si los datos son los que necesitas. En caso de modificar o reformatear datos, necesitas seleccionar un campo de datos del cual deseas modificar el XPath y usar la herramienta de xpath.
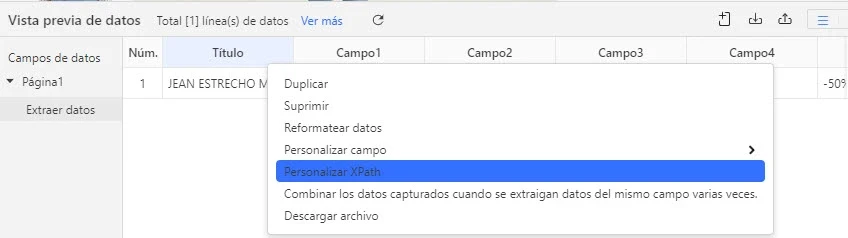
Paso 3: Para modificar XPath, Octoparse proporciona herramieta para la personalización de XPath. Finalmente, puedes modificar XPath, aplicarlo y extraer los datos correctos directamente.
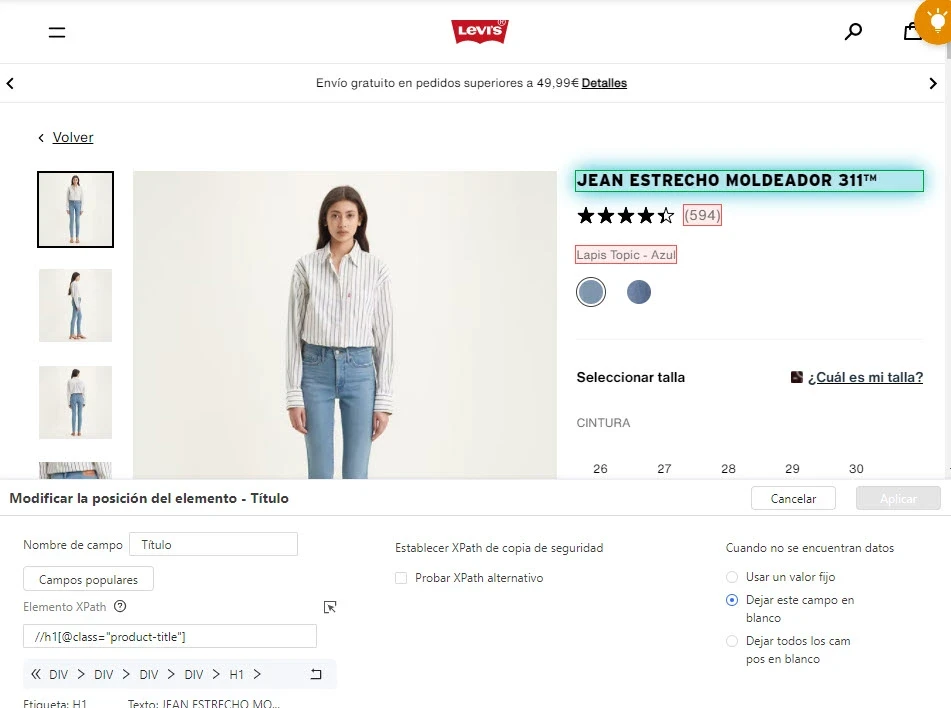
Cómo encontrar Xpath
Si eres un novato total y no tienes idea de términos como “nodo”, “elemento” y “atributo”, primero obtén algunos conocimientos básicos en HTML W3C. A continuación, se muestran algunos cursos intensivos para el aprendizaje de XPath:
Encontrar el XPath correcto en Chrome
1. Copiar Xpath en Chrome
Pasos para encontrar XPath en la herramienta de desarrollo de Chrome:
1) Activar las herramientas de desarrollo de Chrome inspeccionando un elemento en el DOM. Puedes hacerlo apuntando el cursor al elemento DOM de destino y luego haciendo clic con el botón derecho en el elemento de destino. A continuación, puedes seleccionar la opción Inspeccionar elemento en el menú emergente.
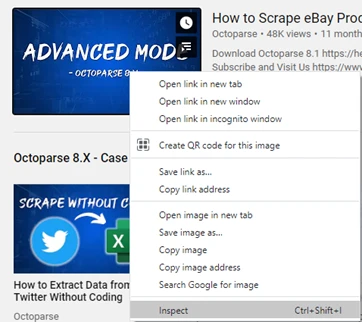
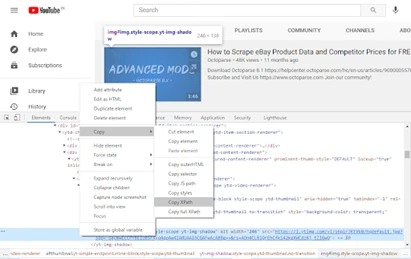
2) Ahora, nuevamente hacer clic derecho en el elemento HTML del destino y copiar el XPath. ¡Fácil!
2. Escribir el tuyo con Xpath Helper
También puedes escribir tu propio XPath utilizando la extensión de Chrome XPath Helper. Además, Octoparse también tiene una herramienta XPath incorporada para facilitarte las cosas. Para escribir tu propio XPath, puedes consultar el tutorial para conocer más detalles.
Conclusión
XPath es una parte integral de cualquier proyecto de web scraping. Herramientas como Octoparse te facilitan la tarea de rastrear la web escribiendo XPaths de manera inteligente bajo el capó mientras apuntas y haces clic en los datos de destino. La nueva e innovadora función de detección automática de Octoparse elimina la necesidad de apuntar y hacer clic. ¡Feliz Web Scraping!




