Cuando se trata de raspado web, Idealista.com es un objetivo de raspado tradicional. Para rasparlo, cubriremos dos técnicas comunes de web scraping: usando un recolector de datos o código Python.
Por último, también veremos cómo rastrear y raspar propiedades recién listadas, lo que nos dará una ventaja a la hora de descubrir propiedades y pujar por ellas.
¿Por Qué Scrapear idealista?
Para las empresas inmobiliarias, disponer de datos en tiempo real sobre el mercado, la oferta, la demanda, el precio y la ubicación puede ser un punto clave para realizar una buena inversión o determinar el precio de venta. Idealista.com es el mayor mercado inmobiliario de España, Portugal e Italia.
¿Es Legal el idealista Scraping?
Es legal scrapear los datos públicos de Idealista.com; es perfectamente legal y ético rastrear los datos de Idealista.com de forma lenta y razonable.
Dicho esto, hay que tener cuidado de cumplir con la normativa GDRP de la Unión Europea al capturar datos personales (por ejemplo, nombres de vendedores, números de teléfono, etc.). Para más información, consulte nuestro ¿Es legal el Web Scraping? .
Maneras para Extraer datos de Inmuebles por Idealista
Aunque idealista dispone de API para acceder a los datos, suele dar muchos errores de respuesta y es muy limitado.
BeautifulSoup – Python
BeautifulSoup se combina con la biblioteca de peticiones de Python para obtener y analizar rápidamente contenido web. En comparación con otros frameworks complejos, BeautifulSoup ocupa poca memoria, se ejecuta rápidamente y puede realizar tareas de extracción de datos de forma eficiente.
Además, puede combinarse fácilmente con otras bibliotecas de procesamiento de datos (por ejemplo, Pandas, NumPy) para facilitar la limpieza, el almacenamiento y el análisis de los datos. Esto es especialmente útil en escenarios donde los datos de Idealista necesitan ser utilizados para análisis posteriores.
Aquí tiene un ejemplo de código python sencillo:
Notas:
Cabeceras de petición: Configure las cabeceras para que imiten la petición de un navegador para evitar ser detectado como un bot.
Estructura de la página web: La estructura HTML de la página web puede cambiar, por lo que es posible que tenga que ajustar los parámetros find o find_all en consecuencia.
Cumplimiento legal: Garantice el cumplimiento de las condiciones de servicio de Idealista. Evite el scraping frecuente o la extracción de datos a gran escala para evitar bloqueos de cuenta o de IP.
Idealista Web Scraper – SIN Codificación
A muchas personas les lleva mucho tiempo aprender y dominar el uso del código en las clases de programación. Entonces, ¿hay una manera fácil de obtener los datos? La respuesta es sí. A continuación utilizaremos la herramienta de captura de datos Octoparse para realizar una sencilla operación.
Antes de que todo empiece, tenemos que descargar Octoparse y preparar un enlace a idealista: https://www.idealista.com/venta-viviendas/valencia/ciutat-vella/sant-francesc/
Paso 1: Introduzca la URL de la lista de propiedades y utilice Auto-detectar para la identificación automática del sitio.
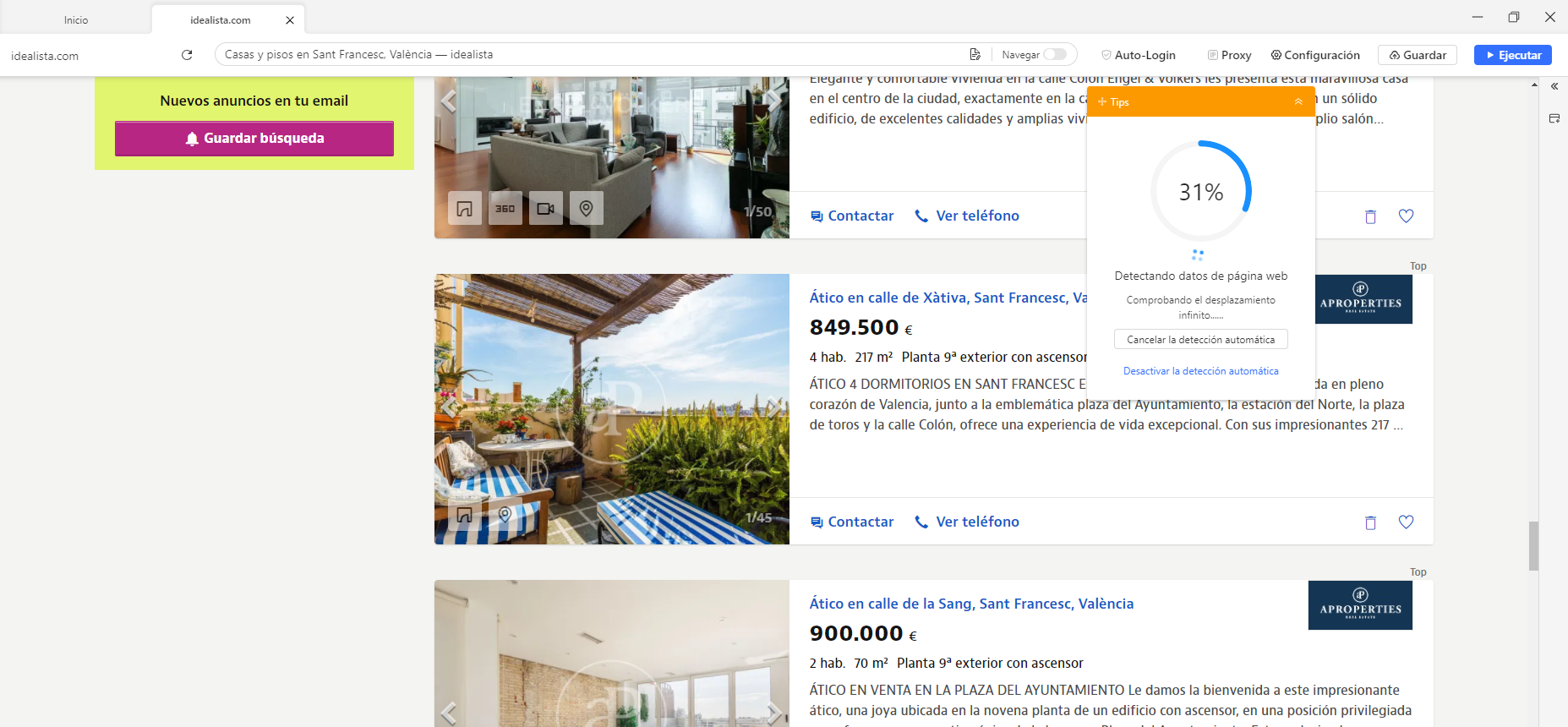
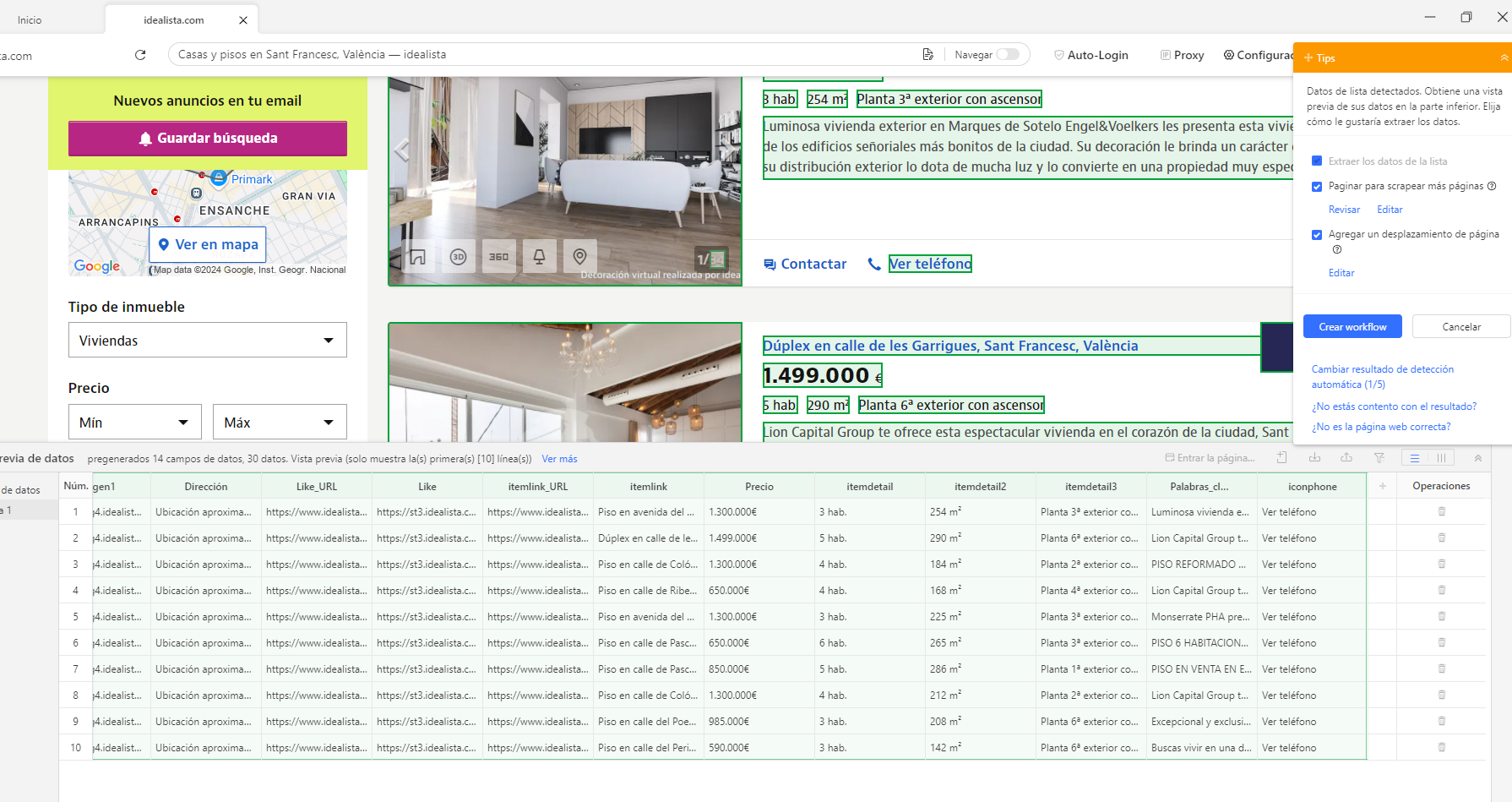
Paso 2: Ver si la prevista de datos cumple las expectativas y Crear workflow
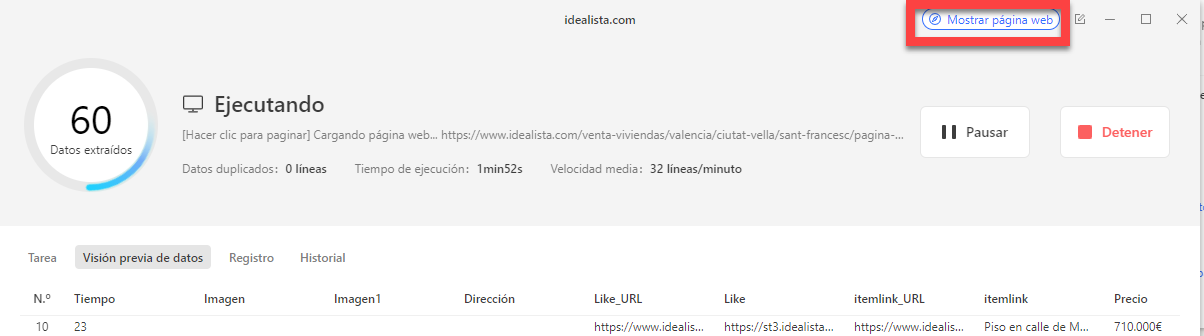
Paso 3: Haga clic en Ejecutar para iniciar el proceso de recogida de datos.
✍️Ojo: Si encuentra que la lista de datos está en blanco, puede comprobar si está atascado con Capthca haciendo clic en “Mostrar página web” y omitiendo manualmente la validación.
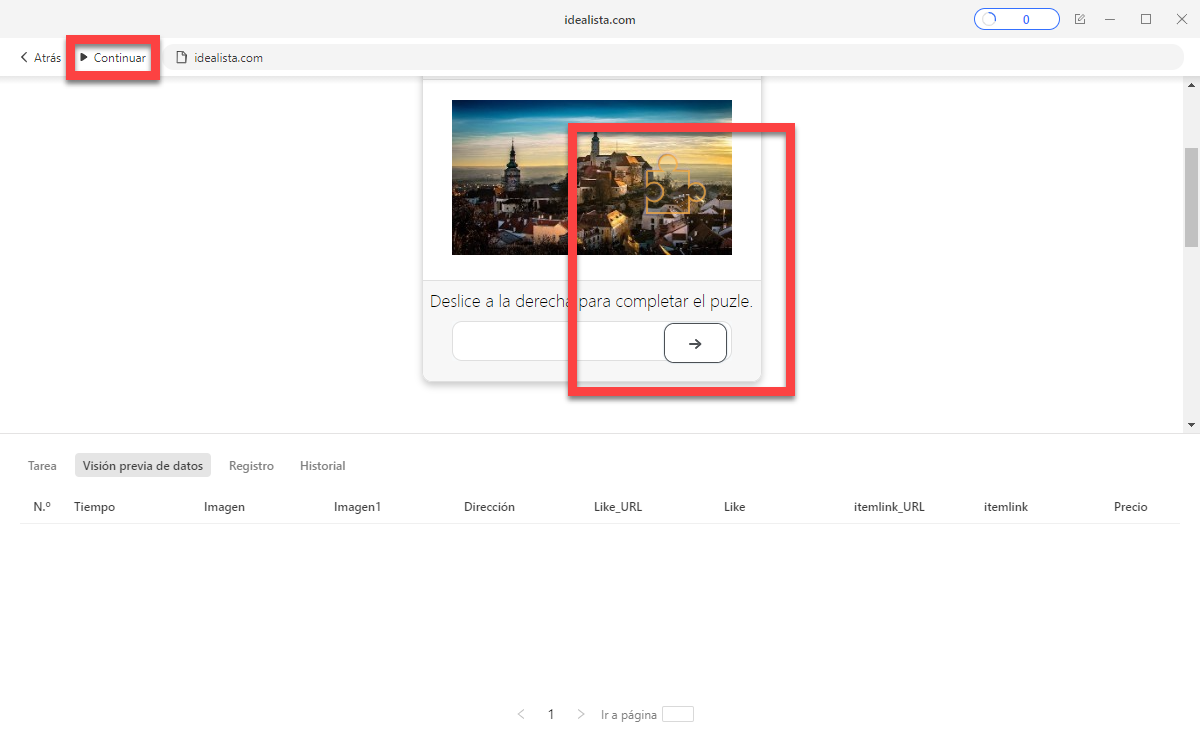
Si desea omitir la validación automáticamente y no desea configurar el flujo de trabajo, pruebe la plantilla de idealista preestablecida Octoparse:
https://www.octoparse.es/template/idealista-listados-scraper
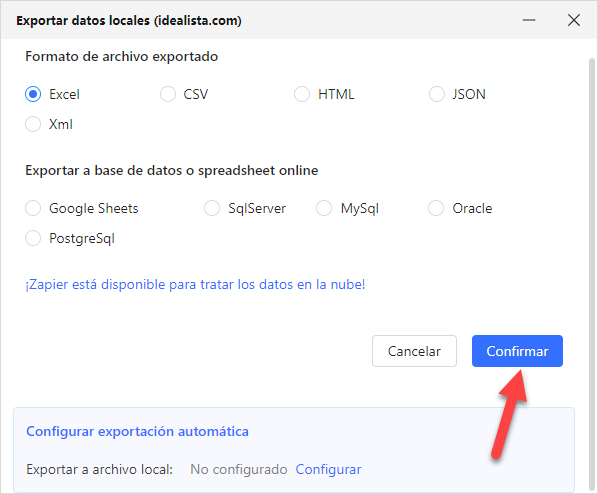
Paso 4: Exportar datos y terminar.
Octoparse admite diversos métodos de exportación de datos(CSV/Json/HTML/Xml), tanto para el análisis diario de datos como para los requisitos de las bases de datos.
Además de Octoparse, existen muchas otras herramientas de raspado de datos para el idealista scraping.
Conclusión
Este artículo explica cómo raspar datos de listados de propiedades en idealista de dos formas sencillas: python y web scraper. Además de las funciones mencionadas anteriormente, Octoparse puede realizar un seguimiento de los nuevos listados publicados en idealista mediante la creación de un flujo de trabajo de scraping recurrente que se actualiza periódicamente.
¿A qué espera? Pruébelo ahora.

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



