Sin lugar a dudas, esta es una era de explosión de información. Se dice que para 2020, habría 44 zettabytes de datos en todo el universo digital. Según de Domo’s data never sleeps 7.0, se crea una cantidad increíble de datos cada minuto:
- Los usuarios de Twitter envían 511.200 tweets
- 188,000,000 correos electrónicos son enviados
- Google realiza 4,497,420 búsquedas
- 18,100,000 textos son enviados
- ……
Muchas personas están plagadas de sobrecarga de información. Quizás tomaría varias horas revisar todas las noticias, correos electrónicos o tweets todos los días, aunque el 80% de ellos no son la información que necesitan. Algunas personas comienzan a cansarse de la sobrecarga de información. Sin embargo, se perderían el 20% de información importante si los ignoran a todos información. Por lo tanto, descubrir alguna forma de extraer solo la información útil realmente importa en este momento. Ahí es cuando surge la minería de texto.
¿Qué es la Minería de Texto (Text Mining)?
La minería de texto es una técnica que podría extraer información de alta calidad entre una gran cantidad de textos. La minería de texto se basa en el procesamiento del lenguaje natural (NLP) y se combina con algunos algoritmos típicos de minería de datos, como clasificación, agrupamiento, red neuronal, etc. Además, hay algunas otras aplicaciones típicas de minería de texto, como análisis sentimental, extracción de información, tema modelado, etc.
¿Cómo hacer un proyecto de minería de texto?
Adquisición de Texto
Antes de hacer un proyecto con habilidades de minería de texto, primero debemos obtener datos sin procesar de alguna parte. La Adquisición de Texto es el primer paso y el más importante antes de la minería de texto.
Para las personas que desean realizar un proyecto de minería de texto, pueden encontrar muchos datos de código abierto de plataformas de datos como Kaggle. Sin embargo, los conjuntos de datos en tales plataformas se han utilizado ampliamente, por lo que es difícil llevar a cabo un proyecto especifíco basado en estas fuentes. Hoy en día, más personas preferirían construir una araña web y scrape datos de first-hand y actualizados de Internet.
Muchas personas escribirían sus propias arañas(crawlers) usando python u otros idiomas para raspar datos en sitios web. Las bibliotecas como BeautifulSoup4, request o Tweepy se han utilizado ampliamente. Pero para aquellos que no tienen una habilidad de programación de alto nivel o no entienden la estructura web tan bien, la programación parece ser el mayor obstáculo para sus proyectos. En este caso, otra opción es utilizar algunas herramientas de web scraping necesarias para la codificación 0, como Octoparse.
Procesamiento de texto
Por lo general, los humanos procesan textos en nuestro cerebro al leerlos línea por línea para comprenderlos y concluirlos. Durante la minería de texto, la computadora borraría automáticamente de cierta información inútil y cuantificaría los textos útiles transformándolos en números.
- Procesamiento lingüístico de textos
Para el proyecto de minería de texto, la computadora no podía entender la semántica de las palabras, por lo que solo podía reconocer palabras basadas en la estructura. Por lo tanto, todo el pasaje de textos se dividiría en unidades de texto específicas, como una oración o, más frecuentemente, una palabra. Tokenization, Lemmazation o Stemming son las formas más comunes de separar todo el texto.
Después de dividir el texto en palabras, podemos clasificarlas de acuerdo con sus partes del discurso. Como sabemos, habría una cadena sin sentido en textos como “una”, “de” o algunos signos de puntuación. Estos textos se llaman stopword. Una última cosa que se debe hacer al procesar texto es eliminar todas las stopwords y conservar solo los datos significativos.
- Procesamiento matemático de textos
Después de separar los textos y eliminar todas las stopwords, podríamos comenzar a hacer un procesamiento matemático, que es cuantificar los textos transformándolos en números basados en diferentes parámetros. El parámetro más común es la frecuencia de palabras (Countvectorizer). Simplemente calculando cuántas veces aparece cada palabra. Hay algunos otros parámetros, como TF-IDF y Word2vector.
Minería de texto
Después de procesar todos los datos, podríamos comenzar nuestros proyectos de minería de texto. Estos son algunos de los ejemplos más comunes de minería de texto:
- Nube de palabras: Cree una nube de palabras según la frecuencia de las palabras. Todas las palabras aparecerían dentro de una nube. Las palabras de alta frecuencia aparecerían más grandes que las palabras de baja frecuencia. Llevaríamos a cabo un análisis de nube de palabras más tarde. (por ejemplo, texto visualización de texto)
- Análisis sentimental: El Análisis Sentimental es un proceso que podría ayudarnos a identificar el sentimiento a partir de opiniones basadas en las palabras. Una biblioteca de Python llamada TextBlob podría ayudarnos a analizarlos y generar un puntaje de fuerza de sentimiento positivo o negativo. (por ejemplo, monitoreo de producto o marca)
- Modelado de temas: El modelado de temas podría ayudarnos a identificar el tema de un texto. Latent Dirichlet Allocation (LDA) es un ejemplo de modelado de temas que podría clasificar el texto de un documento a un tema en particular. Crea un tema por modelo de documento y palabras por modelo de tema, modelado como distribuciones de Dirichlet. (por ejemplo, etiquetado para reseñas/ noticias/artículos)
Aquí le mostraremos cómo hacer un simple análisis de nube de palabras. Rasparemos los tweets sobre “#fashion” y crearemos una nube de palabras para ver cuáles son los vocabularios de alta frecuencia. ¡Háganos saber de qué habla la gente de moda en Twitter!
Minería de textos en X(Twitter) con web scraping
1. Extraer datos con web scraper
Usaríamos la herramienta de extracción de datos – Octoparse para scrapear los tweets.
A menudo, necesitamos estar conectados para asegurarnos de que la recopilación se realiza sin problemas, y la plantilla de rastreo de Octoparse permite recopilar datos de Twitter sin necesidad de conectarse.
https://www.octoparse.es/template/twitter-scraper-by-keywords
Nota: La función de Ejecutar en la nube utilizada por esta plantilla requiere acceso Premium. ¡Pruébela ahora!
En Twitter, debemos seguir desplazándonos por las páginas para cargar más información. Si quieres crear tu propio flujo de trabajo, puedes descargar la aplicación de escritorio y sigue este tutorial: Scrapear tweets de Twitter.
2. Limpieza de datos
A continuación, intentamos recorrer todos los tweets y extraerlos.
Vaya a https://wordart.com e ingrese el texto que acabamos de extraer. En Word Art, podríamos filtrar todos los números, stopwords y también puede realizar análisis derivados del texto. Y también eliminamos “fashion”, que es nuestra palabra clave, ya que sin duda sería la palabra más frecuente.
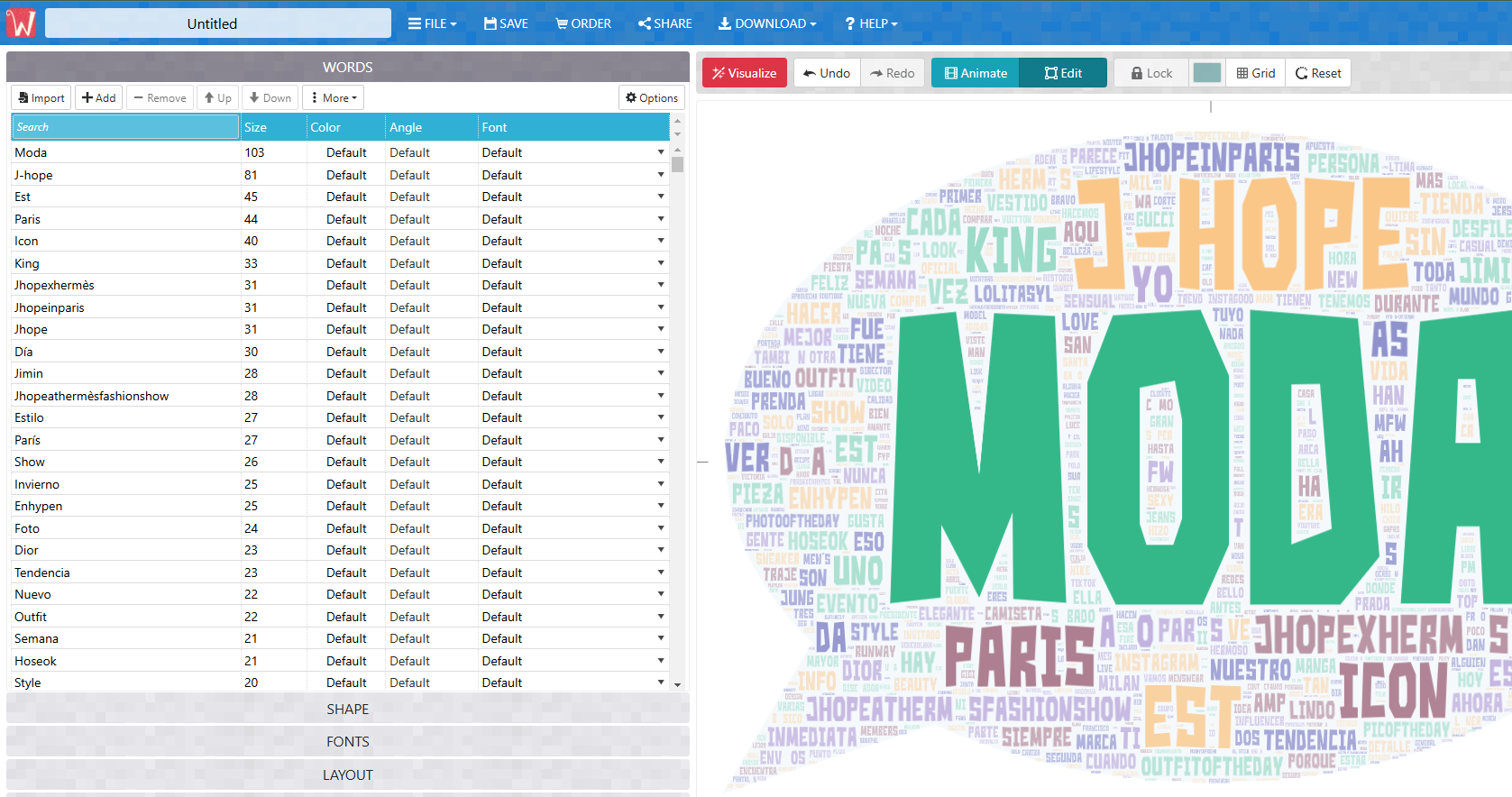
3. Generación de nubes de palabras a partir de datos
Finalmente, aquí está la nube de palabras para #fashion.
Como podemos ver, “Style” es la palabra más frecuentemente mencionada. Además, hay algunas otras palabras de alta frecuencia como “Vestido”, “Amor”, “Nuevo”, “Camisa”, “Tienda”, “Diecisiete” … Esta es la visualización que acabamos de capturar sobre una gran cantidad de tweets.

Así que hagamos algunas suposiciones basadas en la nube. Normalmente, Fashion y Style son lo contrario. Fashion es lo que adora o sigue un gran grupo de personas, mientras que Style es único para relativamente pocas personas. Dado que “Style” ha sido ampliamente discutido en Twitter, podríamos adivinar razonablemente que más personas considerarían compartir sus propios Styles.
Para terminar
¿A quién seguiremos en Twitter? Los estilos de Celebridades de moda serían únicos para ellos, pero sus palabras o tweets se volverían populares. A medida que más personas comienzan a prestar atención a su estilo, su estilo se convertiría en una nueva tendencia de la moda. La influencia de las celebridades en la moda es enorme.
Para tener una idea de lo que la gente habla sobre #fashion en Twitter, no necesitamos pasar mucho tiempo leyendo cada tweet. En lugar. la nube de palabras podría dar un sentido intuitivo del tema relacionado de los textos. Al vincular varias palabras de alta frecuencia, incluso podríamos adivinar el texto e intentar inferir algunos resultados posibles.
Podríamos obtener muchas otras conjeturas de interés con la ayuda de una nube de palabras. Pero, por lo general, combinaríamos la nube de palabras con otros análisis (como el análisis sentimental o el modelado de temas), para buscar más pistas ocultas en los textos. El mundo del texto es asombroso. ¡Por qué no comenzar su proyecto de datos ahora desde Octoparse!

Convetir datos de sitios web en Excel, CSV, Google Sheets y base de datos directamente.
Scrapear datos fácilmente con funciones de Auto-Detectar, sin codificación.
Plantillas de crawler preestablecidas para sitios web populares para obtener datos en clics.
Nunca se bloquee con proxies IP y API avanzada.
Servicio en la Nube para programar la recopilación de datos en cualquier momento que desee.



