La necesidad de crawl data de sitios web ha aumentado en los últimos años. Los datos rastreados se pueden usar para la evaluación o predicción en diferentes campos. Aquí, me gustaría hablar sobre 3 métodos que podemos adoptar para scrapear datos desde un sitio web.
Utilizar Website APIs
Muchos sitios web de redes sociales grandes, como Facebook, Twitter, Instagram, StackOverflow, proporcionan API para que los usuarios accedan a sus datos. A veces, puedes elegir las API oficiales para obtener datos estructurados.
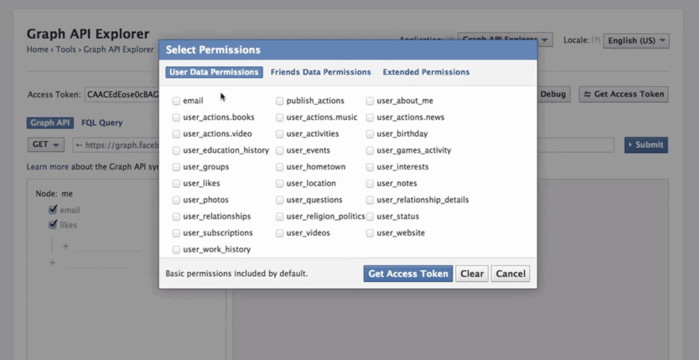
Como se muestra a continuación en la Facebook Graph API, debes elegir los campos donde realiza la consulta, luego ordenar los datos, realizar la búsqueda de URL, realizar solicitudes, etc. Para obtener más información, puedes consultar https://developers.facebook.com/docs/graph-api/using-graph-api.
Construir tu propio crawler
Sin embargo, no todos los sitios web proporcionan API a los usuarios. Ciertos sitios web se niegan a proporcionar API públicas debido a límites técnicos u otras razones. Alguien puede proponer fuentes RSS, pero debido a que ponen un límite a su uso, no sugeriré ni haré más comentarios al respecto. En este caso, lo que quiero discutir es que podemos construir un crawler por nuestra cuenta para hacer frente a esta situación.
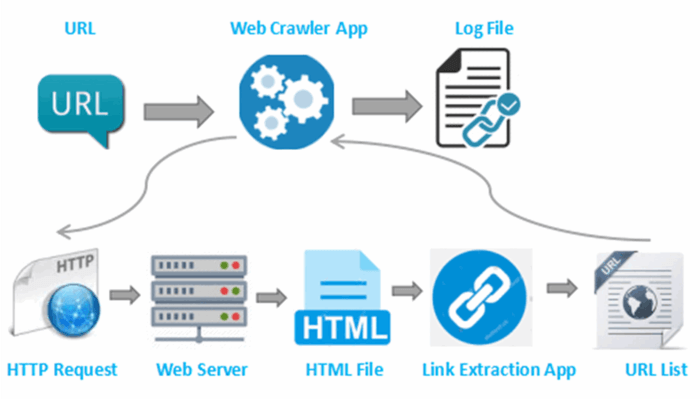
¿Cómo funciona un crawler? Un crawler, un rastreador de datos, llamado sobre todo rastreador web, así como araña, es un bot de Internet que navega sistemáticamente por la World Wide Web, normalmente para crear los índices de un motor de búsqueda. Los crawlers se pueden definir como herramientas para encontrar las URL. Empresas como Google o Facebook utilizan el rastreo web para recopilar los datos todo el tiempo.
Primero le da al crawler una página web para que comience, y ellos seguirán todos estos enlaces en esa página. Entonces este proceso continuará en un bucle.
Entonces, podemos proceder a construir nuestro propio crawler. Se sabe que Python es un lenguaje de programación de código abierto, y puede encontrar muchas bibliotecas funcionales útiles. Aquí, sugiero BeautifulSoup (Python Library) porque es más fácil de trabajar y posee muchos carácteres intuitivos. Más exactamente, utilizaré dos módulos de Python para crawl los datos.
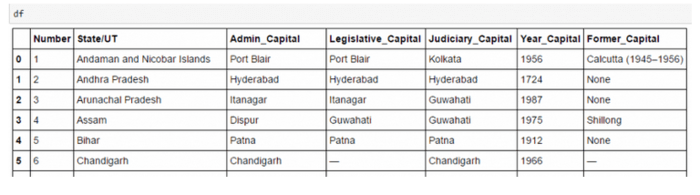
BeautifulSoup no obtiene la página web para nosotros. Por eso uso urllib2 para combinar con la biblioteca BeautifulSoup. Luego, debemos lidiar con las etiquetas HTML para encontrar todos los enlaces dentro de las etiquetas <a> de la página y la tabla derecha. Después de eso, repitimos cada tr (td) y luego asignamos cada elemento de tr (td) a una variable y añádalo a una lista. Primero veamos la estructura HTML de la tabla (no voy a extraer información para la título de la tabla <th>).
Al adoptar este enfoque, tu crawler se personaliza. Puedes lidiar con ciertas dificultades encontradas en la extracción de API. Puedes usar el proxy para evitar que algunos sitios web lo bloqueen, etc. Todo el proceso está bajo tu control.
Este método debería tener sentido para las personas con habilidades de codificación. El marco rastreado de datos debe ser como la figura a continuación.
Aprovechar las herramientas de web crawling
Crawl un sitio web por tu cuenta mediante la programación puede llevar mucho tiempo. Para las personas sin habilidades de codificación, esta sería una tarea difícil. Por lo tanto, me gustaría presentar algunas Crawler Tools.
Octoparse
Octoparse es un poderoso web data crawler basado en Windows y Mac. Es realmente fácil para los usuarios comprender esta herramienta con su interfaz de usuario simple y amigable. Para usarlo, no necesitas escribir códigos. Con solo hacer clics e ingresar URLs o palabras clave, podrás extraer datos de una página web que quieras. Como se muestra en la figura a continuación, puedes activar el modo de detección automática. También puedes hacer clic y arrastrar los bloques en el panel derecho de Workflow para personalizar tu propia tarea.
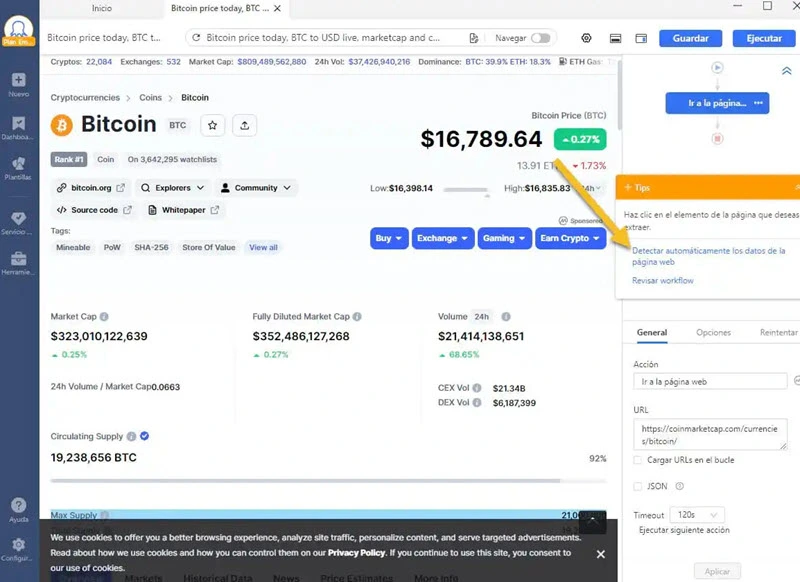
Además, puedes probar 300+ de plantillas de Octoparse, que cubren las necesidades de datos de la mayoría de los sitios populares, como de Amazon, Google Maps, Twitter, Páginas Amarillas, Mercado Libre, Idealista, etc. Así empezar tu viaje de extracción de datos haciendo solamente clics e ingresando URLs.

Octoparse según los requisitos de la extracción de datos proporciona cuatro planes para los usuarios: el gratuito, el estándar, el profesional y el empresarial. Con un plan gratuito ya puedes realizar la mayoría de tus necesidades de datos de una página web.
Y si quieres probar los servicios de la extracción en la nube para exportar tus datos de una página web aunque cierres sesión, o exportar los datos a tu base de datos, puedes activar los planes premium o primero solicitar 14 días de pruebas gratuitas. De 6 a 14 servidores en la nube ejecutarán tus tareas simultáneamente con una mayor velocidad y crawl a mayor escala. Además, puedes automatizar tu extracción de datos sin dejar rastro utilizando la función de proxy anónimo de Octoparse que podría rotar toneladas de IP, lo que evitará que ciertos sitios web lo bloqueen.
Octoparse también proporciona API para conectar su sistema a sus datos scrapeados en tiempo real. Puedes importar los datos de Octoparse en tu propia base de datos o usar la API para solicitar acceso a los datos de tu cuenta. Después de finalizar la configuración de la tarea, puedes exportar datos a varios formatos, como CSV, Excel, HTML, Json, Google Sheets y database (MySQL, SQL Server y Oracle).
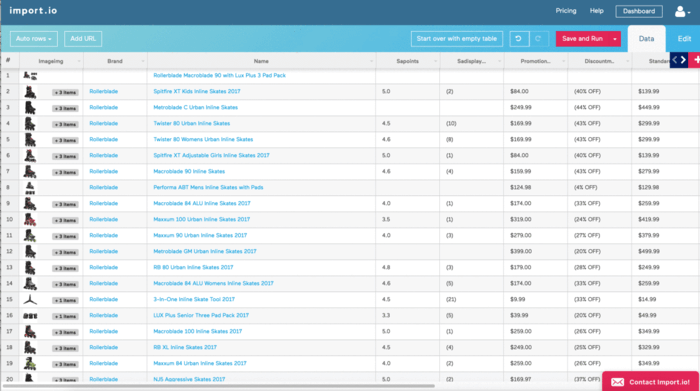
Import.io
Import.io también se conoce como un web crawler que cubre todos los diferentes niveles de necesidades de crawling. Ofrece una herramienta mágica que puede convertir un sitio en una formar sin ninguna sesión de entrenamiento.
Sugiere a los usuarios descargar su aplicación de escritorio si es necesario crawl sitios web más complicados. Una vez que hayan creado su API, ofrece una serie de opciones de integración simples, como Google Sheets, Plot.ly, Excel, así como solicitudes GET y POST.
Cuando considera que todo esto viene con una etiqueta de precio de por vida y un equipo de soporte increíble, import.io es un primer elección claro para aquellos que buscan datos estructurados. También ofrecen una opción paga de nivel empresarial para empresas que buscan una extracción de datos más compleja o a gran escala.
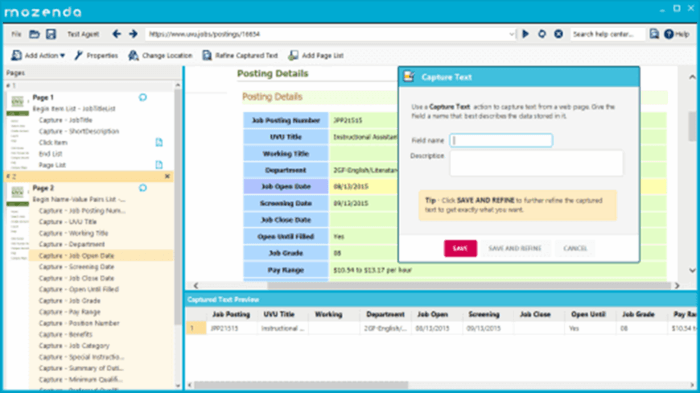
Mozenda
Mozenda es otro extractor de datos web fácil de usar. Tiene una interfaz de usuario de apuntar y hacer clic para usuarios sin ninguna habilidad de codificación para usar. Mozenda también elimina la molestia de automatizar y publicar datos extraídos. Dile a Mozenda qué datos deseas una vez, y luego los obtienes con la frecuencia que los necesites.
Además, permite una programación avanzada utilizando REST API que el usuario puede conectar directamente con la cuenta Mozenda. Proporciona el servicio basado en la nube y la rotación de IP también.
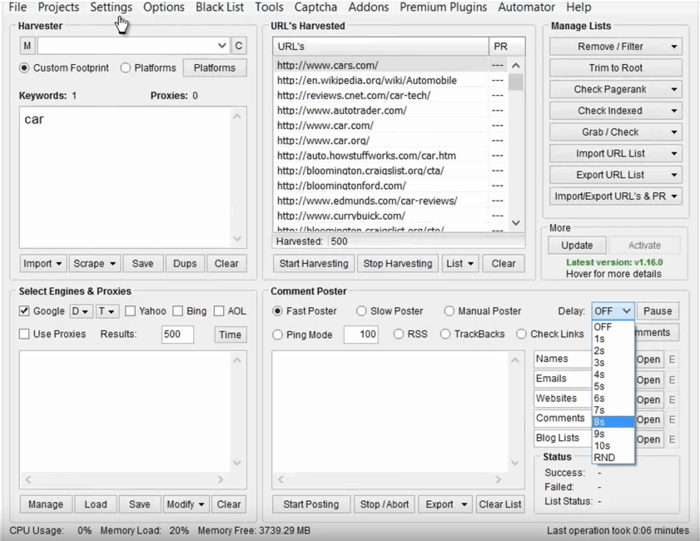
ScrapeBox
SEO expertos, los vendedores en línea e incluso los spammers deberían estar muy familiarizados con ScrapeBox con su interfaz de usuario. Los usuarios pueden recolectar fácilmente datos de un sitio web para recibir correos electrónicos, verificar el rango de la página, verificar los servidores proxy y el envío de RSS. Mediante el uso de miles de servidores proxy rotativos, podrá escabullirse de las palabras clave del sitio de la competencia, investigar en sitios .gov, recopilar datos y comentar sin ser bloqueado o detectado.
Google Web Scraper Plugin
Si la gente solo quiere scrapear datos de una manera simple, le sugiero que elija el complemento Google Web Scraper. Es un web scraper basado en navegador que funciona como Outwit Hub de Firefox. Puede descargarlo como una extensión e instalarlo en su navegador. Debe resaltar los campos de datos que desea scrapear, hacer clic con el botón derecho y elegir “Scrape similar …”.
Todo lo que sea similar a lo que destacó se representará en una tabla lista para exportar, compatible con Google Docs. La última versión todavía tenía algunos errores en las hojas de cálculo. Aunque es fácil de manejar, no puede scrapear imágenes y crawl datos en gran cantidad.
Estas son para nosotros las mejores formas de crawl datos desde sitios web, pero hay muchas más soluciones para crawl datos de páginas de forma automatizada o profe, depende de la situación de cada uno. Así que tan solo tienes que elegir la que mejor se ajuste a tus necesidades.